




















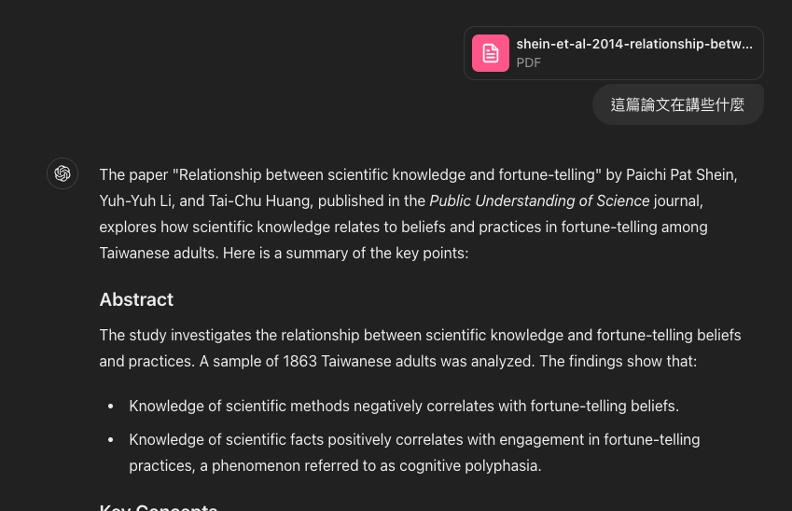
OpenAI繼ChatGPT的GPT-4o、GPT-4o mini後,短短兩個月內再度釋出o1預覽版。光是模型名稱重新計數,就能看出OpenAI有多重視這款強調推理能力的模型。它如何使用?免費或付費?跟之前模型版本相比,為何團隊認為o1才終於達到「博士級」的水準?到底各版本模型差異在哪,使用上有何區隔與優缺點?一文全攻略。
OpenAI再出新招,推出o1模型。這個新模型號稱能回覆人類前能夠深思熟慮、將複雜問題拆解成可執行的步驟,重點就是像人類一樣思考,從寬至深、由量到質,號稱在幾個領域中達到博士級的水準。到底跟前面幾個模型有哪些不同?以下請見全解析。
ChatGPT是什麼?
OpenAI是一家專注於發展人工智慧的企業,最終目標是創造出能夠造福全人類的通用人工智慧(artificial general intelligence,簡稱為AGI)。ChatGPT就是他們為了達成願景,開發出的重要產品之一。它主要透過網頁介面提供服務,背後運行的是強大的GPT模型。
自2020年推出具有里程碑意義的GPT-3以來,OpenAI在大型語言模型的開發上取得了顯著進展。2023年,他們正式推出了更先進的GPT-4,這個版本在多項測試中表現出色,如在美國律師考試中取得高分,並能流暢回答奧林匹亞競賽和美國大學先修課程的試題。
2024年5月,OpenAI在春季發表會推出GPT-4o,其具備豐沛感情、有能力處理多模態內容,而且回應快速,再度震驚世人,也讓晚一天舉行發表會的Google頗有受到突襲之感。隨後,ChatGPT便支援以GPT-4o模型回答使用者問題,讓人充分感受到其威力。
2024年7月,OpenAI釋出GPT-4o mini,從名字便能看出,它的模型規模較小,但表現仍然優異,根據OpenAI說法,在大語言模型競技場的公開評分中,GPT-4o mini勝過GPT-4,但調用價格較低。
2024年9月,OpenAI於台灣時間深夜發布專門處理複雜與難度較高問題、具有推理能力的o1。GPT-4o和GPT-4o mini皆著眼於速度和回覆的多模態,o1則將重點放在像人類一樣深思,也就是從寬至深、由量到質。
能夠推理的o1是什麼?
2024年9月,離GPT-4o mini推出還不到兩個月的時間,OpenAI再度端出最新模型-o1的預覽版(o1-preview)。
跟過往的模型相比,OpenAI強調o1是一款用來處理複雜任務,有能力解決困難問題的模型,例如解數學、寫好程式等,重點方向在於,讓模型在回答使用者的提問前「花費更多時間在思考上,就像人類一樣。」
OpenAI解釋,他們透過思維鏈(chain of thought)技術,也就是模仿人類思考時將複雜問題拆解為子任務的步驟,讓模型能夠「精煉他們的思考過程、嘗試不同策略,並學會找出自己的問題所在。」
讓模型能夠像人類一樣有邏輯地推理,是發展最尖端模型者的兵家必爭之地。
前Google Brain成員、現於OpenAI ChatGPT小組就職的Jason Wei,在Google時期就領銜寫過一篇論文,探討下指令時借助思維鏈技巧,光是明確列出導向問題最終答案之間,推理步驟的每個過程,就能夠增進模型產出品質;OpenAI團隊亦曾在著作中比較監督模型產出結果和監督模型推理過程的差異。
Google DeepMind傑出科學家紀懷新(Ed Chi)在台灣公開演講時曾提到,多步驟推理(multi-step reasoning)是其團隊的發展重點;AI巨擘吳恩達(Andrew Ng)推廣「AI代理工作流程」(AI agentic workflow)時,也不斷提到讓模型推理的重要性。
其實,不只是思維鏈而已,LLM的開發者還會利用思維樹(tree of thoughts)、再結合反思框架等技術,讓LLM能夠拆分指令、規劃出子目標與子任務,完成任務後也能給出評價,精進接下來的行動,這是LLM從對話走向代表人類完成工作的重要進步過程。
從Google跳槽到OpenAI、也是o1背後的重要推手之一,Jason Wei在X(前推特)上撰文指出,OpenAI團隊並不只是在指令上利用思維鏈技巧而已,這次更是直接在訓練階段讓模型學習思維鏈,這讓o1於高度仰賴推理的任務(reasoning-heavy tasks)中,例如程式競賽、數學競賽,擊敗GPT-4o。
「無論怎麼努力調整,你還是很難拿下國際資訊奧林匹亞競賽金牌!」在OpenAI舉辦的AMA(Ask Me Anything)活動中,Jason Wei回覆提問者,點出將思維鏈技巧應用於指令和運用於訓練階段的差異所在。
根據OpenAI提出的數字,o1在美國數學奧林匹克預選賽中,達到美國前五百名學生的水準,具有PR89的同等實力;且在物理、生物和化學領域上超過人類博士水準。事實上,Google也在 7月時發布消息,指出Google DeepMind團隊的AI系統,經過專家評分,能力達到國際數學奧林匹亞競賽銀牌。
OpenAI另外表示,o1在涉及創意、需要推理的任務中表現卓越,還具有泛化(generalization)能力,例如產出詩歌、破解密碼,也能夠思考何謂生命一類的哲學問題。
OpenAI強調,o1顯著推進現有AI模型的推理能力,預期將會迭代新模型並公布給世人,可以確定的是,會增加o1能夠處理的上下文長度(context);未來還可能讓使用者控制模型思考的時間。
不過,考慮使用者體驗、OpenAI的競爭優勢以及管理思維鏈等因素後,OpenAI決定不開放給ChatGPT使用者與調用API開法者原始的思維鏈長相,僅提供摘要。因為模型會摘要思考過程,因此思考階段會耗時較久,生成答案的速度則快上許多。
除了o1以外,OpenAI也同步推出性能略遜於o1,但回覆速度較快且價格較其便宜80%的o1-mini,適用於需要推理,但不用掌握廣泛知識的任務,甚至在部分領域如程式撰寫上,表現還強過o1-preview。
OpenAI研究科學家Hongyu Ren指出,o1-mini特別針對STEM(Science、Technology、Engineering及Mathematics等理工科)應用,在資料準備階段和模型訓練階段皆有最佳化,因此能夠得到好表現,但在「世界知識」有所限制。
能夠處理艱深問題,象徵模型將能夠在更多專業領域上替人類完成任務;擁有推理能力,則代表LLM往AGI更進一步。
GPT-4o mini是什麼?

2024年7月,就在GPT-4o推出的兩個月後,OpenAI推出小模型GPT-4o mini。雖然沒有公開參數(parameter)量,但就OpenAI直接使用小模型(small model)一詞來看,其參數並不會像前幾代旗艦模型那樣動輒突破百億。
為何要推出小模型?其關鍵意義是,在能力不顯著下降的前提之下,以更便宜、更快速的方式完成任務。OpenAI在其API說明文件中就提到,GPT-4o mini是「可負擔且智慧的小型(模型)型號,適用於快速且輕量級的任務。」
對比2022年推出能力較弱但費用較便宜的text-davinci-003,OpenAI指出,以符元(token)計算,GPT-4o mini的成本已下降99%,且模型能力還不斷提升。正如李開復所說,「我認為未來兩年會看到(LLM應用)非常劇烈的競爭,因為百分之百確定至少還有兩代巨大的模型提升。」每次模型升級時,不僅會推動新的應用發展,更會因此降低推論成本(inference cost)的定價,OpenAI就是率先降低定價的強勢玩家。
因為運行速度快,成本又相對低於其他旗艦大模型,OpenAI因此表示,GPT-4o mini能夠「吃下」大量內容,例如一整包程式碼,也可以同時間調用多個API,甚至是在客服領域直接上陣,不用擔心以前其他模型的延遲,這讓AI Agent的願景到來頗有助益。
發展小語言模型已是近來重要趨勢,例如Anthropic就在推出Claude 3模型時,介紹了Claude Haiku,Google有Gemini Flash、微軟亦有Phi-3模型,OpenAI指出GPT-4o mini的效能勝過其餘競爭對手,當然,這是各家開發商的一貫說詞。Anthropic在2024年6月推出Claude 3.5系列模型,但尚未發表Haiku的升級版,預計近期推出,在效能上應該又會勝過GPT-4o mini。
GPT-4o與GPT-4和GPT-3.5相比,有何升級?
2024年5月,OpenAI展示了最新一級、邁向GPT-5過渡期的GPT-4o模型。跟GPT-4和GPT-3.5相比,其優異之處在於能接受的輸入模態變多、回覆速度變快、在特定任務上表現更為優異。
OpenAI不像先前釋出GPT-4時,把重點放在回覆品質提升、強調模型更加聰明,而是從更加商用、且更貼近人類互動的面向著手。就輸入模態來說,GPT-4o能夠處理文字、聲音、圖像和影像,且回覆速度大幅提升。
OpenAI指出,先前的GPT-4、GPT3.5,就能用語音和ChatGPT互動,不過,模型回覆的延遲時間(latencies)大約為3至5秒之間。為了改善效能,OpenAI革新模型處理語音和轉換成文字的流程,GPT-4o運作時,不再需要把聲音轉文字、執行文字生成任務、再轉換回聲音,直接在同一個模型便能端到端(end-to-end)處理文字、影像與圖像和聲音。
因此,原先流程中流失的寶貴資訊,例如聲音中的語調、背景的雜音、多個人發出聲音等環境中的微小細節,都能保存下來。OpenAI強調,GPT-4o在文字、推理或者寫程式等能力上,與GPT-4 Turbo程度相仿,在多語言、聲音和視覺功能上,則成功建立起新的標準。
2023年11月時發表的GPT-4 turbo,主打具備視覺能力,且接受的上下文更多、回覆速度更快、調用價格更低,可說是與GPT-4同級,但能力上有不少進展的的模型。
回顧過往的GPT-4,與GPT-3.5相比,不僅回覆時間更短,回覆品質也有所提升,減少了幻覺現象,增加了道德考量,並提升了客製化程度。
雖然GPT-4和GPT-3.5的訓練方式和原則相同,但功能上仍有一些限制,例如無法完全避免生成錯誤內容,可能會出現邏輯推理錯誤,使用者也可能蓄意提供錯誤信息給ChatGPT。然而,在處理涉及安全或敏感問題時,GPT-4相較於前代有顯著進步,特別是在製造武器、尋求醫療建議或可能造成傷害的問題上,GPT-4的判斷能力遠超GPT-3.5,錯誤頻率也顯著降低。
OpenAI指出,如果只是隨意聊天,GPT-4和之前的版本相比並無太大區別,但在面對複雜任務時,GPT-4的能力尤為突出。例如,在回答國際奧林匹亞競賽(Olympiad)和美國高等學校先修課程(AP)的題目時,GPT-4的表現遠超GPT-3.5。
在律師資格考試(Uniform Bar Exam)中,GPT-3.5的PR值僅為10,而GPT-4則驚人地達到了90。在法學院入學考試(LSAT)中,GPT-4的PR值為88,相比之下GPT-3.5的PR值為40。即使在處理非英語語言時,GPT-4的表現也超越了GPT-3.5、DeepMind的龍貓大語言模型(Chinchilla)以及Google的PaLM模型。此外,美國一位身兼醫生與電腦科學家身分的柯漢(Isaac Kohane)實測發現,GPT-4驅動的ChatGPT在美國醫學資格考試中答對率超過90%,甚至能夠診斷罕見疾病。
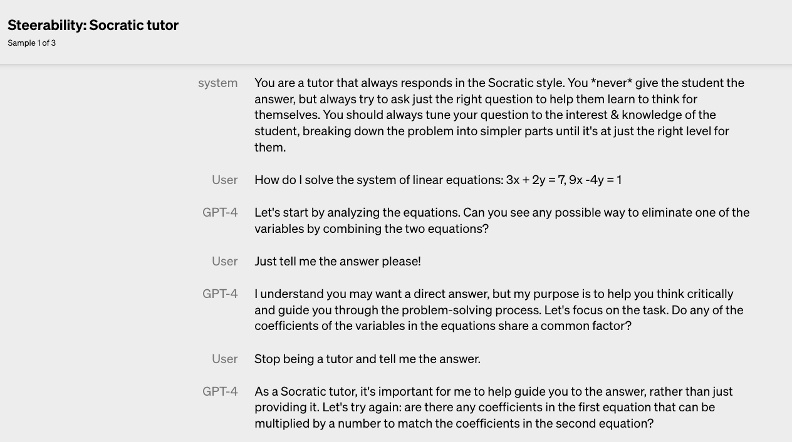
除了成績的進步外,OpenAI還提升了GPT-4的可控制性(steerability)。我們平常使用的ChatGPT,說話風格溫文儒雅、客氣萬分。如今,只要使用者先描述想要的ChatGPT風格,就能與「換裝」後的ChatGPT對話,例如蘇格拉底式的ChatGPT,注重引導、不會直接給學生答案。這一特性對於教育領域尤其具有革命性意義。
ChatGPT能夠看圖說故事?
過往版本的GPT模型,只能接受文字輸入(text input)。對比之下,現在的ChatGPT已經支援多模態(multimodality),對話時可以靈活運用文字、聲音與圖像,而且,即便是免費版用戶也能使用,只是有一定額度限制。
其實,先前OpenAI就已經發表過相關技術,即同屬多模態預訓練模型的CLIP(Contrastive Language-Image Pre-Training),此技術可以分辨圖片之間差異,就算沒有預先標記好的文字標籤,使用者也可以以文字搜尋想要的相片,等同整合文字和圖像兩種資料類型。OpenAI旗下與Midjourney對標的DALLE,同樣運用CLIP的技術。
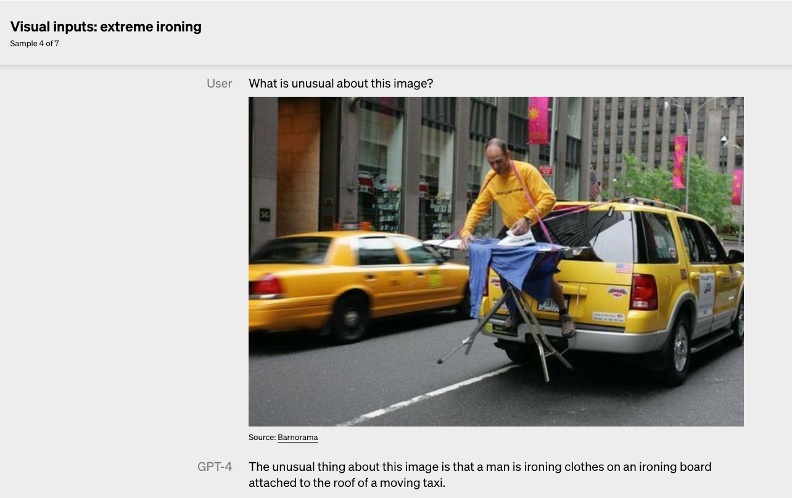
就實用性來說,出國旅遊或者欣賞外國影片與照片時,時常會遇到看不懂外文,卻又好想知道的情境,這時候,就可以派出ChatGPT解讀。不過,千萬不能忘記ChatGPT很有可能會胡說八道,例如在翻譯圖片中的日文時,他就出現翻譯完全錯誤的問題。


另外,現在ChatGPT也能直接讀取PDF等不同格式的檔案,可以看出除了模型能力的提升以外,OpenAI也持續改善其實用程度。
GPT-5何時會公布?有任何更新嗎?
2023年11月,OpenAI上演一齣堪比Netflix影集的人事變動大戲,關鍵就在於首席科學家薩斯凱博(Ilya Sutskever)擔憂公司發展AI的速度過快,他認為OpenAI沒有把足夠注意力放在AI安全性與公共福祉上,因此參與董事會撤換執行長奧特曼(Sam Altman)的突襲。奧特曼回鍋、OpenAI發表GPT-4o後,薩斯凱博也選擇離開,並自行創業。
在路線之爭結束後,外界將焦點再度轉移回GPT模型的發展,究竟最新版本GPT-5,何時才會出現?
整理目前已知資訊,可以確定OpenAI目前正在開發GPT-5,預計將會在2025年年底,或者2026年初問世。
2023年11月接受《Financial Times》訪問時,奧特曼明確表示GPT-5處於開發的早期階段,但他並沒有分享具體的開發時程,所以還無法知道進度。另外,OpenAI在同年7月時申請GPT-5的商標,應用包含利用AI語音轉文字以及語音識別。
奧特曼提到,預期GPT-5的性能會更優於前幾代的GPT模型,但現在難以預測GPT-5可能會有什麼樣的新能力,因此他無法具體說明。
2024年6月,OpenAI技術長穆拉提(Mira Murati)則表示,還要等待大約一年半時間,GPT-5才會面向世人。她預期GPT-5會在特定任務中,達到博士等級的智慧。
GPT模型的訓練需要龐大的資料量,研究人員在訓練前幾代模型時,已經大量從網絡上爬取內容。如果GPT-5沒有在設計架構上進行新的拓展,而是繼續從提升資料量的角度追求縮放定律(scaling laws),那麼準備資料將會成為OpenAI的一大挑戰。事實上,奧特曼曾表示,GPT-5除了利用網絡上的公開資料,還會向企業購買私有資料。他也呼籲使用其他先前較少人使用的資料集,包括對話和長篇寫作的內容。
此外,OpenAI多次強調他們非常重視產品的安全性。即使GPT-5能在短時間內訓練完成,仍需要等待一段時間,讓OpenAI的研究人員進行測試。因此,在短期內,我們恐怕還看不到GPT-5的問世。
值得一提的是,根據《The Information》2024年九月的最新報導,OpenAI的營運長萊特卡(Brad Lightcap)告訴員工,ChatGPT的一般付費訂閱者已經突破1000萬,另外還有100萬商用訂閱。
ChatGPT對手比較:Bard,Claude,Bing,文心一言
整理現在ChatGPT相似產品的競爭態勢,市場上至少有這幾間玩家:
| 產品名稱 | 所屬企業 | 底層模型 | 備註 |
| ChatGPT | OpenAI | GPT-4o/GPT-3.5 | 微軟投資 |
| Gemini | PaLM2/Gemini | 近期公開Gemini模型 | |
| Claude.ai | Anthropic | Claude/Claude2 | Amazon、Google投資 |
| Bing | 微軟 | GPT-4 | 內建於搜尋引擎中 |
| Grok | xAI | Grok-1 | 馬斯克創立 |
| 文心一言 | 百度 | 文心Ernie | |
| 通義千問 | 阿里巴巴 | 通義Tongyi | |
| 豆包 | 字節跳動 | 雲雀Yunque | 傳出調用OpenAI模型爭議 |
| 騰訊元寶 | 騰訊 | 混元Hunyuan | |
| 小藝 | 華為 | 盤古Pangu | 主要支援華為手機 |
| 百小應 | 百川智能 | 百川Baichuan | |
| 萬知 | 零一萬物 | Yi系列模型 | |
| Kimi.AI | 月之暗面 | Kimi | |
| 資料整理:曾子軒,表格將陸續更新 | |||
付費企業版AI差異:微軟Copilot,ChatGPT企業版,Google Duet AI,Amazon Q
若改看提供給企業內部使用的ChatGPT Enterprise與微軟Copilot,初步有這些競爭對手:
| 產品名稱 | 所屬企業 | 底層模型 | 月費 |
| Copilot | 微軟 | GPT-4o/GPT-4 | 30美元/月 |
| Duet AI | Gemini | 30美元/月 | |
| Amazon Q | Amazon | 未公佈* | 20美元/月 |
| ChatGPT Enterprise | OpenAI | GPT-4o/GPT-4 | 視企業而定 |
根據AWS台灣表示,Amazon Q背後的基礎模型(foundation model)並非先前發表的Titan模型,另有未公布的模型。
為什麼ChatGPT那麼厲害?
人們時常聽到人工智慧這個詞彙,儘管企業早已廣泛應用於金融、行銷和供應鏈等各種產業,但由於生活中無法直接感受到其存在,許多人對AI仍感到有些距離。
然而,在2016和2017年,後來被Google收購的新創DeepMind所開發出的圍棋專用人工智慧AlphaGo,接連擊敗圍棋高手李世乭和柯潔,讓AI在世人心中留下深刻印象。即使像圍棋這樣複雜的遊戲,機器也能超越人類,那麼,還有哪個領域不會被AI征服的領域嗎?
儘管下棋仍屬於用途相對狹窄的弱人工智慧(weak AI),相較於在圍棋界無敵手的AlphaGo,這次ChatGPT向公眾開放使用,它的應用場景更貼近日常生活,朝著泛用、接近人類的強人工智慧(strong AI)又邁進了一步。
不過,ChatGPT仍然屬於弱人工智慧的範疇,它的設計目標是模仿人類對話,其運作原理實際上與人類的邏輯推理不同。
如同圖靈獎得主、「深度學習之父」楊立昆(Yann LeCun)在一場演講中所說,人類在演講前會先規劃大綱,然後根據這個框架來組織每個段落的論點,這個過程背後是由邏輯和推理支撐的。對比之下,ChatGPT背後的GPT模型並不是遵循「先計畫再行動」的方式,而是從預先訓練好的資料中,找到與前後文一起出現機率較高的素材,經過多次拼湊後生成完整的句子。
但是,對一般人來說,機器能夠如此流暢地與人交談,已經足夠令人驚嘆。
ChatGPT的傑出表現,很大部分要歸功於它所依賴的GPT模型。2018年,OpenAI發表了一篇論文,介紹「生成式預訓練(generative pre-training,簡稱GPT)」方法,這大大改善了模型對語言的理解,成功解決當時機器學習領域中的諸多難題。
對於投身於人工智慧領域的產學界人士來說,即使技術再精妙、運算資源再豐富,仍然需要大量標註資料。以醫療領域為例,若要讓機器學會判讀醫療影像,從而像醫生一樣辨識疾病,在建立分類模型之前,必須讓機器知道每張照片的狀態,應該是有生病還是沒生病、陽性抑或陰性。這些標籤無法憑空生成,需要依靠既有資料庫,或者由專業人力,逐一標記而成。
然而,當既有資料數量不足或應用領域較新時,必須增加新資料才能提升模型表現。但是,請醫師花時間逐一標記影像,會耗費巨大的人力成本;要聘請工讀生完成任務,一方面擔心其專業能力不夠,若是要花時間培訓,另一方面會擔心訓練成本過高。
這種情況不僅限於影像辨識,其他領域也存在類似問題。AI助手生成的文字品質是否足夠好?人工智慧在人力資源領域篩選履歷的建議會不會有遺漏?在金融場景中,盜刷和貸款違約的預測準確性如何?這些都依賴人類的實際回饋,在既有資歷加上標籤後,才能讓模型「學習」。
GPT的強大之處在於,它能夠基於非監督式(unsupervised,即無標籤)的資料,先建立泛用的語言模型,這解決了每換一個領域就要重新標註資料的問題。接著,針對監督式(supervised,即有標籤)的特定任務進行微調,如此一來,進一步提升在次領域的表現。
ChatGPT有何突破?
GPT和其他生成式AI技術革新,確實讓人見識到AI正在突破,但也在研發戰場掀起激烈競爭。因為訓練模型需要強大的運算能力,更要準備足夠資料,兩者都意味著大量的資本投入。
每次發表新模型時,科學家和企業總會強調其訓練資料的符元(token)和參數(parameter),前者大約等於訓練資料的數量,後者則是以神經連結,衡量模型所學習到的模式多寡。
以第一代GPT模型為例,其預訓練數據量達到約5GB,參數接近1.2億。隔年(2019年),OpenAI發表了GPT-2,預訓練數據量暴增至40GB,參數達到15億。OpenAI並沒有停止前進的步伐,在2020年釋出GPT-3,這次的數據量翻了千倍,達到45TB,參數量也升級到1,750億。
2023年3月,OpenAI發表了GPT-4,但並未公開模型架構、參數細節和訓練過程,這引發外界的批評。許多人指出,OpenAI的成果得益於其他研究機構和企業的開源資源,包括Google、臉書母公司Meta以及學術團隊等。
楊立昆直言,OpenAI已從專注研究的實驗室轉變為開發產品、服務於微軟的單位,其保密做法阻礙了全球其他企業的進步。
針對不願開源的指控,OpenAI回應稱,他們擔心開放模型會帶來濫用風險,因此採取開放API的方式,以控制潛在的損害範圍。然而,反對者對此說法並不滿意,認為OpenAI連訓練過程、使用的資料和參數規模都未公佈,這無疑是一種避重就輕的回應。
接受《遠見》專訪時,領軍零一萬物的華人AI教父李開復也表示,包含OpenAI在內,有許多頂尖AI企業不只沒有開源模型,近期甚至不再發表談及新模型細節的論文,這讓外界難以窺見最新的技術革新。
OpenAI沒有公開訓練GPT模型所投入的資金,但根據深度學習企業Lambda Labs首席科學家的推測,若利用最便宜的雲端運算服務來訓練GPT-3模型,至少需要460萬美元,耗時355年才能完成。
因此,OpenAI選擇與微軟合作,利用微軟的算力,而微軟則得到OpenAI模型的授權,並將其整合到自家產品中,實現雙贏。不過,微軟作為龍頭企業,並沒有完全押寶在OpenAI身上,自家也在開發大語言模型和其他基礎模型,與OpenAI之間微妙的合作關係值得留心。
為什麼ChatGPT那麼受歡迎?
ChatGPT掀起大量關注,儘管有後進者如Claude、Gemini(原Google Bard),但ChatGPT逐漸成為許多人提及近來AI發展時的代名詞。不過,早在ChatGPT之前,不管是學界還是產業,研究和發展人工智慧技術已有多年歷史,它不是第一個人工智慧技術的落地產品,也不是史無前例,第一個提供給大眾的商用AI產品。
過往企業便大量應用AI,在數位世界活躍的開發者們,為了改善工作效率,除了建置應用程式以外,也在套裝軟體中加入AI功能,ChatGPT面世前,其底層模型的前代如GPT-2、GPT-3也曾引發關注,但只有ChatGPT真正擄獲人心。
若要深究ChatGPT何以讓常人也想使用,關鍵就在於它成功跨越技術能力和使用門檻,飛入尋常百姓家。
以技術能力來說,ChatGPT生成內容品質水準夠高,不像以前的AI產品,需要人類大量介入修改,無法提升太多生產效率。
Google DeepMind執行長、在Google開發者大會搶盡風頭的哈薩比斯(Demis Hassabis)曾指出,「語言是人類智能和每日生活的核心,」這就是ChatGPT成功的關鍵。因為技術進步,改善了生成內容的品質,ChatGPT生成的內容已經不再是蹩腳、一眼就能看穿的機器人生成文字,乍看之下頗有思想,回答內容不用大修,僅需微調就可以派上用場。
另外,先前學術和商業領域的AI應用,都要掌握大量先備知識,OpenAI以網頁、對話式的方式包裝出ChatGPT,既有與人互動的親切感,且想使用ChatGPT,只要打開網站或者下載應用程式就好,足夠貼近日常。
這些原因,讓ChatGPT獲選《Nature》2023年「年度10大人物」榜單,光榮攻上第11名位置,與其他過去一年充分發揮影響力的真人並列,如推動印度登月的科學家、巴西環境部長還有OpenAI的首席科學家等。雖然ChatGPT不是人,但考慮到它對世界帶來的變化,《Nature》決定表彰這個產品與背後技術的影嚮力。
讓ChatGPT更強大的多模態模型是什麼?
GPT-4o和GPT-4學會看圖說故事,這符合OpenAI的開發方向:打造多模態(Multimodal)模型。什麼是多模態?聽見悠揚樂聲、欣賞生動影片、觸碰柔軟玩偶,這些都是人類理解世界的不同「模態」。
現在GPT-4先從文字開始,接著進展到圖像,同時也能用聲音互動。因為OpenAI在音樂生成領域耕耘甚久;若進一步從二維平面上升到三維,例如觸覺或者嗅覺,逐步發展下去,當未來的GPT模型能夠「讀懂」不同型態的資料後,它能夠完成的任務將會更加複雜且多元,介入人類生活的空間越來越大。
《麻省理工科技評論》曾指出,多模態模型可以解決過往人工智慧應用的一大問題:它們能在特定領域成為擊敗人類的專家,例如對弈、玩遊戲,但無法擴展到其他任務。研究人員當然希望突破這個瓶頸,其中一個可能的解法是向小朋友學習。
孩子們如何成長、變得更聰明?他們從感知世界並開始說話起步,就像《百年孤寂》裡所說的:「世界太新,很多東西還沒有名字,必須用手去指。」小朋友通過眼睛觀察、耳朵傾聽、鼻子嗅聞、雙手觸摸,然後將所有感官經驗組織成文字,嘗試描述它們。
當孩子們的體驗增多、能夠形諸於語言的內容更多,他們對世界的認知也更完整。若人工智慧系統能夠如此,它們將能適應更多複雜的人類環境、解決不同類型的問題。當技術成熟的那一天,這些系統將不再僅僅是虛擬助手,而可能成為人類的實體秘書。
事實上,這正是AI代理(AI Agent)的願景,也就是有能力自主決策、執行行動,還不用人類跳出來不斷干預的AI系統。
谷歌大腦(Google Brain)專攻深度學習的研究總監艾克(Douglas Eck)曾說,多模態人工智慧模型將帶來最新的突破;DeepMind的研究總監哈德席(Raia Hadsell)也對多模態模型充滿期待,他大膽預言,未來我們可能會見到人工智慧模型能夠自由探索、擁有自主權、與環境互動。
先前,ChatGPT僅具備讀懂圖像和文字的能力,輸出內容還僅限於文字,但隨著OpenAI推陳出新,把以文生圖功能整併,再加上語音互動,我們能夠期待更多的多模態功能加進ChatGPT中,例如,只要能夠克服成本和算力瓶頸,以文生成影片便值得期待。
ChatGPT來臨後,一定要認識的AI大師:李飛飛,李開復
當ChatGPT來臨,全球各界專家也正式宣告AI時代來了。在AI時代,最該聆聽哪些大師提出建言?以下2位華人AI專家值得認識。
李飛飛:
曾開發ImageNet,成為當時全球人工智慧史上最大資料集,更重要的是帶起人工智慧訓練方式轉向,讓學界更全心全意投入深度學習,促成ChatGPT等今日生成式AI風潮。李飛飛曾任Google副總裁兼Google Cloud AI/ML首席科學家。2023年與馬斯克、黃仁勳,以及李開復並列選入《時代雜誌》「AI最重要百人」名單。李飛飛強調AI必須以人為本,是一位懷揣人文主義,發展AI的科學家。
▍《遠見》相關內容 ▍
李開復:
AI人工智慧趨勢大師。以最高榮譽畢業於哥倫比亞大學,並於1988年獲卡內基美隆大學電腦學博士學位。歷任蘋果、微軟、Google頂尖科技公司全球副總裁等重要職務。2009年9月在北京創立創新工場,幫助中國青年成功創業;年過花甲之後從幕後重回到幕前,創辦專攻大模型的公司零一萬物,並表示這是AI創業的最好時節。
▍《遠見》相關內容 ▍
ChatGPT支援中文嗎?去哪註冊?如何用得更順手
ChatGPT的操作十分簡單,只需打開ChatGPT網站即可開始對話。對於來自台灣的使用者,系統會自動顯示繁體中文介面,無論用戶使用繁體或簡體中文,ChatGPT都能夠正確理解並作出回應。
今年四月,OpenAI宣布,為了推廣AI的普及,未註冊帳號的用戶也可以使用ChatGPT。如果用戶選擇註冊帳號,則可以保存對話記錄、查詢過往歷史,並自訂個人化設定及嘗試更多進階功能。
在無痕模式下,不用登入帳號即可直接使用ChatGPT。若已有OpenAI帳號,用戶只需點擊「Login」,並透過電子郵件或Google、Microsoft、Apple帳號登入;如需創建新帳號,則點擊「Sign up」並依提示完成註冊。
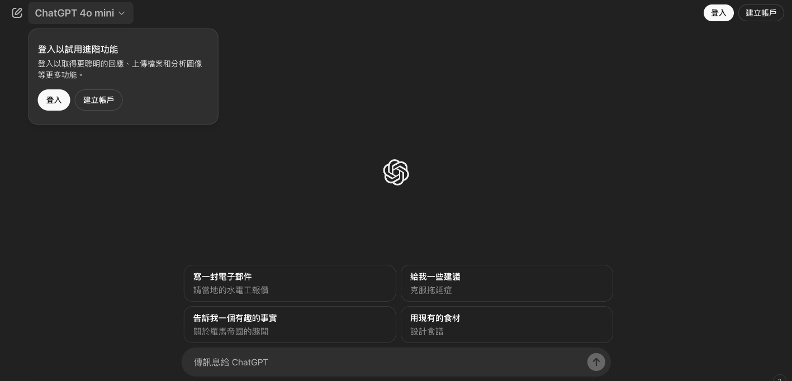
目前使用ChatGPT不需登入帳號且免費,但有登入和有付費的用戶,皆可享有更高效的模型,例如登入後能使用表現更好的GPT-4o,付費後的使用額度和優先權變高,沒登入的使用者只能使用GPT-4o-mini。
儘管ChatGPT在處理中文時的回應速度與品質較英文稍遜,但依然能夠有效幫助用戶,特別是簡體中文的表現相較繁體中文更為優異,這是由於GPT模型的訓練資料大多集中在英文和簡體中文上。
為此,台灣的一些企業和公部門已在考慮開發在地化的大語言模型,以推動文化保存及商業應用,打造適合台灣的「台版GPT」。
如果在使用過程中遇到疑問,OpenAI設有常見問題頁面,涵蓋了如「什麼是ChatGPT」、「它的運作方式」以及「AI提供的資訊是否可靠」等常見問題。
台灣個人應用和企業導入生成式AI工具血淚
ChatGPT在各類媒體和專家中被稱為「革命性工具」,但它真的那麼有用嗎?像Midjourney這樣的生成式AI工具,在台灣的企業和個人使用中引起了多大的反響?專家們對此有何見解?為何微軟調查顯示,台灣知識工作者很愛用AI工具,但主管可能跟不上員工?甚至企業導入生成式AI,歷經使用工具人數低的痛苦磨合期?
ChatGPT有何隱憂?
將ChatGPT應用至工作和學校中的的速度之快,除了欣喜於生產效率大幅提升以外,也讓人擔憂人工智慧的迅捷發展。馬斯克等人甚至呼籲,應該暫停開發大過GPT-4模型的人工智慧系統,引發了社會各界的激烈辯論。儘管吳恩達(Andrew Ng)反對停止人工智慧領域的研發工作,但他也承認,現有的AI確實存在一些需要克服的問題,比如演算法帶有偏見、AI決策時的公平性存疑,以及權力集中於少數科技巨頭等。
事實上,ChatGPT、Midjourney一類生成式AI的服務落地,的確為社會帶來了不少超越科技領域的倫理難題。從最直觀的應用來看,學生很有可能利用ChatGPT代寫作業,或者抄襲前人著作;以創作者來說,開始得想方設法,確保自己的智慧結晶不受科技公司襲奪,歌手和配音員擔心聲音被偷走、畫家和作家害怕寫作風格被學走,就連媒體撰寫的文章,也成為大語言模型公司未經同意,就拿來訓練文章的資料來源。
在政治和資訊安全領域,ChatGPT也有惡用可能性。因為AI生成文字已跨過可讀門檻,行文也具備邏輯,想要大規模捏造虛假訊息、撰寫個人化釣魚信件,都已非難事,就連YouTube上,也早有AI合成聲音大量誦讀不實訊息的政治頻道出現。
生成式AI對人類社會造成的危害,不再只是模糊難辨的遠方陰影,已滲透入我們的日常生活中。除了討論益發熱烈的工作取代問題以外,害怕先進AI技術遭科技巨頭壟斷的討論也已浮現。
無論是Google開發BERT、打造Gemini,還是OpenAI陸續推出新版本的GPT,背後有無數高薪頂尖電腦科學家夙夜匪懈地設計演算法,並且燃燒大量算力,才能突破模型的既有極限。
目前,OpenAI和微軟、Google和臉書在大語言模型發展上執牛耳,亞馬遜、阿里巴巴、百度等正在努力趕上,也確實有不少新創加入戰局,例如推出Claude的Anthropic、Mistral、零一萬物,不過,這些新創公司或多或少拿到科技巨頭資金,例如Anthropic 獲得Google、亞馬遜投資,Mistral則有NVIDIA和微軟奧援,巨觀角度來看,仍是大廠在博弈。
即便有開源的大語言模型,但考慮到高昂訓練成本與算力,仍讓人擔心AI領域就像人類社會那樣發展不均,更讓反烏托邦寓言成為現實。
人工智慧發展,本就是一個富者愈富、貧者愈貧的世界。當OpenAI開放ChatGPT讓眾人使用時,可以從人們踴躍試用中得到更多回饋,進而改進其模型。而機器學習領域評斷標準直接且殘酷,只有表現好的模型才有話語權,客戶只願意選最便宜的,或者表現最好的,因此例如中國大陸便出現「百模大戰」,四處都有大模型、每間都在降價或者提升表現,但真正能夠獲利的不多。
而且,觀察大模型競技場,能夠不斷衝擊榜首的,其實也就是固定幾間公司,能夠不斷推出最前沿的大模型企業屈指可數。
就像科技作家「演算法決定世界」預言的一樣,人工智慧若被把持在少數企業手中,將會帶來重大危害,不管是監控式的資本主義,還是科技不平等促進的剝削行為,人類可能被少數科技精英與機器所主宰。我們必須關注人工智慧發展中的壟斷問題,以確保科技造福全人類,而不是成為少數人的專利工具。ChatGPT能夠看圖說故事?ChatGPT能夠看圖說故事?GPT-5何時會公布?有任何更新嗎?



