




















大語言模型的競爭殺聲震天,OpenAI、Google、META等大公司每個月都在出招。接下來大語言模型有何發展?為什麼小語言模型(SLM)成為兵家必爭之地?上下文長度不斷提升,又有何意義?其他如多模態、AI代理也是觀察重點。大語言模型發展趨勢,《遠見》訪問專家一文帶你看。
大語言模型是什麼?
從OpenAI的GPT系列模型,到臉書的LLaMA系列模型,再到Google的PaLM系列模型,以及後續的Gemini,還有Anthropic的Claude、Mistral的的Mixtral,這些科技巨頭和新創極力發展的大語言模型(Large Language Model),是當下人工智慧產業最受關注的次領域。
大語言模型是以轉換器架構(transformer)為基底,以巨量內容訓練、擁有百億級參數(parameter)的神經網絡模型。不管是支撐ChatGPT的的GPT-3、GPT-4,或者是Google Gemini背後的Gemini,全都是大語言模型。
2018年,OpenAI發表GPT-1、Google推出BERT,兩者同樣使用預訓練技術,參數都是以億計算。雖然尚未達到大語言模型的規模,但仍然為日後技術進展奠定穩固基礎。
在增加模型大小、表現更佳的縮放定律(scaling law)指引下,研究者持續增加模型的參數量與資料量,並在過程中發現,大語言模型的能力遠勝於更早之前的預訓練模型,因此以「湧現」(emergence)稱呼此變化。
對比1750億個參數的GPT-3和15億級的GPT-2、5400億個參數的PaLM與3.4億級的BERT,不管是在遵循指示、理解脈絡上,前者都遠勝於後者。大語言模型能處理的任務不再侷限於原先語言模型預測詞彙機率的功能,可以用來處理更加通用(general)的任務。
大語言模型趨勢1:打造小語言模型,放進地端裝置
去年(2023)9月,微軟推出「僅有」13億個參數的語言模型Phi-1。當時,OpenAI已發布規模在千億級以上的GPT-4,對照之下,Phi-1的大小只能用迷你能形容。
隨後,微軟在12月推出27億個參數的Phi-2,今年4月則公佈Phi-3系列模型,其中以Phi-3-mini的38億個參數最小、Phi-3-medium擁有140億個參數最大。為何科技巨頭們一邊增加訓練資料量、增加模型參數量,努力把模型變得更大,另一邊又要發展小語言模型(Small Language Model,簡稱為SLM)?
Google開發者專家、亞太智能機器創辦人吳柏翰解釋,發展小語言模型的原因在於因地制宜。當模型變小,首先就能放進地端裝置當中,這是AI PC、AI手機實現的重要前提;再者,則是在某些無法聯網的使用情境派上用場,例如工廠產線。
在Google領導包含PaLM、Gemini等諸多大語言模型專案,Google DeepMind傑出科學家紀懷新(Ed Chi)告訴《遠見》記者,如果把模型放入裝置例如手機,如果模型更小,耗能會變少、佔用記憶體空間也會降低,手機因此能夠運作更久。作為科學家,他的努力方向就是在模型規模下降的同時,仍維持其能力。
另外,當模型變小,因為運算時間變少,回覆延遲(latency)因而降低,「這方面的優化,絕對是科學家想要探討的一個極限。」
工研院資通所副所長黃維中補充,小模型能做的事情,大模型也能做。要放著能力更強的大模型不用,轉向使用小模型,背後一定有原因,「用大的模型耗費資源、幻覺多,而且規模太大,不一定能放在『自己家』。」
不過,BERT、GPT-1,參數都是億級,規模上近似於近兩年問世的小型語言模型,兩者有何區別?吳柏翰指出,「小模型這件事情是一個新的變革,因為以前小模型沒有那麼聰明。」換句話說,小模型雖然參數變少許多,但模型能力依舊強大。以Phi-1為例,在微軟研究人員執行的程式撰寫測試中,其能力介於GPT3.5和GPT-4之間,但參數量不到GPT3.5的百分之一。
從另外一個角度來看,因為參數量變小,運算時間變短、耗能降低,把任務交給小語言模型,代表就著省錢與高效率,這也是OpenAI釋出GPT-4o mini時的宣傳重點。
吳柏翰預期,因為在地端運作,小語言模型的發展趨勢是降低耗能,這是百億以下、參數較少的小語言模型,適合放進裝置當中;另一方面,他認為還會有百億至千億之間,專注於處理單一場景中的工作,在垂直領域上應用的小語言模型,「絕對不要讓它什麼都會,一定是特定、制式的。」規模再往上,就進入到千億級參數大語言模型的範疇。
大語言模型趨勢2:有人追逐縮放定律,有人轉向
就像半導體業發展遵守摩爾定律一樣,縮放定律是研發大語言模型者向前的根基。

作為經驗上的定律,縮放定律提出有一段時間,目前仍是LLM研究者遵循的準則。取自Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., ... & Amodei, D. (2020).Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
縮放定律指的是,只要給定訓練資料量、模型參數量和運算量,就能估算訓練出的語言模型表現,「其實GPT-3.5出來的時候,大家都是走scaling law的概念,確認資料大小、神經網絡深度,大概就能預判模型有多聰明。」吳柏翰解釋。
為何縮放定律重要?因為對開發者來說,這不只讓成本變得可控,也讓開發者知道,只要提升任一個因素,就能打造出更強大的模型。
黃維中表示,當資料、參數和運算量越多,模型的表現越好,從數學理論來看是正確的;「湧現」門檻也是數學上的已知,目前觀察縮放定律仍成立,尚未被突破。因此能夠期待開發者訓練模型時,持續增添資料、增加模型參數。
吳柏翰補充,不管是GPT-4或者LLaMA-3,都在擴增模型大小,這是可預期的發展方向,不過,因為縮小模型生成內容品質也能維持,開始有更多研究者另闢蹊徑。
「人的腦神經大概是85個B到120個B,有可能不繼續做大,想辦法把它(LLM)做得貼近人,Google有這種方向。」雖然「越大越好」還成立,但吳柏翰以Google參數30億的視覺語言模型PaliGemma和90億與270億參數的Gemma 2為例,他認為Google可能因為要營運Google生態系,例如在Google Workspace背後配備AI,又要實現人人都能使用AI的願景,因此必須適度降低成本,在產品後放上小語言模型就是合理做法。

紀懷新則說,一定會有團隊繼續試著把模型做得更大,但現在擴大模型面臨挑戰,難度不在參數多寡,也不是算力資源,而是資料。
「能夠蒐集到沒有著作權問題的資料數量,已經達到很高極限。」因此,他預期研究者會把重心從參數量轉移到資料,加緊腳步提升資料品質,例如不只預測下個符元(next-token prediction),挑戰在資料裡面放進思維鏈(chain-of-thought)。
另外,紀懷新也和不同領域的專家取經。舉例來說,最近他找上研究複雜系統(complex system)的物理學家,共同探討大語言模型的湧現現象,如湧現門檻與邊界究竟何在。「神經網路跟物理之間的關係是非常深的,因為訓練方式和熵(enthropy)和最大似然估計(maximum likelihood)都有關係。」
大語言模型趨勢3:提升上下文長度,往無限符元前進
除了模型參數量往千億靠攏,大語言模型的上下文(context)窗口,也就是能夠處理的符元(token)長度,正在不斷提升。
舉例來說,Google今年5月釋出Gemini 1.5 Pro時,表示其上下文窗口已高達200萬個符元。吳柏翰表示,已經在研究中看到有模型能夠處理高達1000萬個符元,之所以尚未公布,「我覺得是在等市場變動,如果Claude說要出100萬,那(Google)就出100萬,GPT下一代200萬那我也跟進。」
模型能夠處理的符元長度逐步增加,甚至往「無限上下文」(infinite context)逼近,這會帶來什麼影響?
黃維中指出,當上下文窗口不斷提升,最直接的好處體現於產出品質。「現在可以讀的內容是有限的,只給他幾百個字,吸收到的資訊就不夠精確。」就像人類讀書一樣,只讀一個章節和讀完整本書,後者考試時一定表現比較好。
吳柏翰表示,過往要讓模型執行任務時,有時會單純描述任務而不提供範例(zero-shot),或者只能在指令中放進數個範例(few-shot),原因便是上下文長度的限制。所以,開發者會以微調(fine-tune)模型,提升其在特定領域的表現。
隨著模型單次能夠處理的資訊量提升,在指令中提供範例的上下文學習(in-context learning)效果跟著變好,微調就不再是唯一可行的到路。「你給我上下文,就可以直接理解所有東西。」在指令(prompt)放入充沛資訊,因為模型能夠完全消化,因此可以提出高品質的回答。
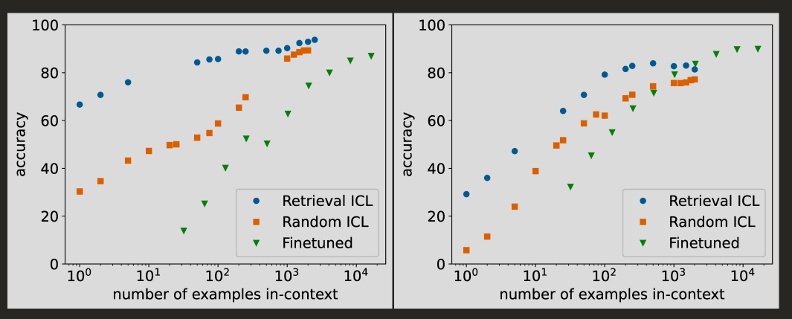
隨著模型能夠處理的上下文長度上升,上下文學習開始成為微調的替代方案。圖為上下文學習(ICL)和微調的效果比較。取自Bertsch, A., Ivgi, M., Alon, U., Berant, J., Gormley, M. R., & Neubig, G. (2024). In-context learning with long-context models: An in-depth exploration. arXiv preprint arXiv:2405.00200.
大語言模型趨勢4:追求更多模態,往垂直領域邁進
從OpenAI公布GPT-4的視覺能力以降,使用者便密切關注模型的多模態能力,因為日常生活中有許多任務會牽涉到圖片和聲音,這就不是先前專注處理文字的大語言模型能處理。
黃維中表示,發展多模態是推進大語言模型的重要方向,「世界就是多模態的,可以處理的面向更廣,現在以文字加圖像為主,影像開始出現。」例如,Gemini 1.5 pro和GPT-4o,都能夠處理影像。
吳柏翰補充,現在還沒看到具備領域知識的多模態模型,「比如專攻化學領域,要能讀懂化學複雜的工作流程,又能處理圖像、文章甚至是影片,這部分還不是很多。」
當多模態模型現身於垂直領域,就能夠記下老師傅的化學製程、在生產線上的動作,這是下一個重要發展方向。

大語言模型趨勢5:AI代理人興起,人人都能打造Agent
不管是Google的Project Astra,或者是GPT-4o的即時回應,都企圖讓有能力自主做出決策、完成行動的AI代理(AI Agent)滲透人類生活。
黃維中分享,早在1950年代,達特茅斯會議定義人工智慧領域之際,便有人想讓AI扮演代理,替人類分憂解勞,日後每次技術進展,都會有人重提AI Agent的願景,例如近年很受關注的RPA(機器人流程自動化)就是寫好規則,讓機器執行任務。
對比之下,「跟生成式AI結合在一起之後,Agent能夠做得變得更多。」因為AI Agent拆解使用者指派的任務後,不管是判斷還是執行準確率,都比以往還高,讓人開始期待生成式AI賦能AI代理。不過,黃維中提醒,雖然AI代理概念屢被提起,但距離大規模落地為時尚早,現在市面上主要還是以讓AI擔任副駕駛(copilot)的協作方式為主。
以能力來說,OpenAI安全系統負責人、曾領導AI應用研究的研究科學家Lilian Weng曾撰文表示,AI Agent以LLM為大腦,擁有規劃技能(planning skills),具備記憶力(memory),同時能夠調用工具(tool use),因此有能力執行通用的任務。
除了探討AI Agent應該具備的能力,吳柏翰認為,技術發展降低開發AI代理和自動化的門檻也值得關注。「以前要特定的人,例如會寫程式的人去做,現在下指令就可以。另一個突破在於,以前要像RPA一樣寫好流程,現在只要描述給AI聽,就能完成需求。」因為建置AI代理變得簡單,一般人也能在生活中完成,這對AI代理普及頗有助益。
作為Google AI代理計畫Project Astra的幕後推手,紀懷新分享,旗下Gemini團隊有三個研究重點,包含複雜的推理能力、進階的規劃和程式碼撰寫,以及原生的多模態能力。
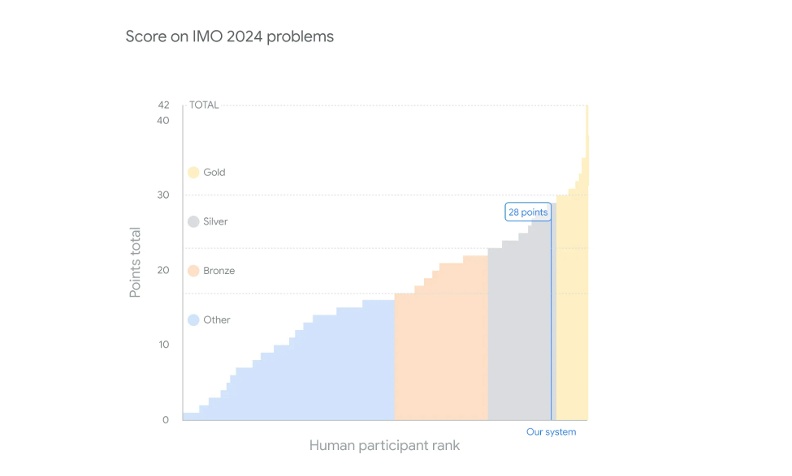
舉例來說,本月(7)Google DeepMind團隊旗下開發的人工智慧系統,經過專家檢驗評分,能力已經達到國際數學奧林匹亞競賽銀牌等級。「這需要很強的多步驟的推理(multi-step reasoning)的能力才能做到。」雖然已經有好表現,但紀懷新認為,LLM的推理能力仍有不少挑戰。
大語言模型從「數大便是美」開始,讓人見識到規模帶來的效益。從研發階段到面對消費者以後,更多商業場景出現,因此模型逐漸縮小,以便放進裝置還有無法連接網路的場域中。再往下走,往無限上下文邁進,提升多模態能力,並且驅動AI Agent發展,大語言模型的能力和應用,正在逐漸開展,走向世界的每個角落。



