




















ChatGPT底層的大語言模型是什麼?語言模型發展從機率和統計開始,進步到神經網絡驅動,預訓練技術出現又開啟新時代;參數量大到一定程度後,湧現強大能力,讓大語言模型擄獲人心。在大語言模型現身之前,語言模型經歷過哪些發展,才走到今天?《遠見》完整解析,有5大要點你必須知道,才能看懂ChatGPT背後的AI浪潮發展方向。
語言模型是什麼?
從ChatGPT、Gemini再到Claude,以大型語言模型(Large Language Model,LLM)為基底賦能的生成式AI應用,讓世人將目光重新聚焦在人工智慧上,其實,早在大語言模型遍地開花之前,語言模型(Language Model)便經歷長期發展。
在自然語言處理(Natural Language Proecessing,NLP)領域中,語言模型是最為基礎且重要的課題之一,這個研究領域主要關心語言單位(linguistic units)例如詞彙,在文字序列中出現的機率分布,當模型能夠掌握人類語言和文章的規則和模式後,就能應用在翻譯、語音辨識和生成內容等多樣任務。
一篇由Google著名電腦科學家米可洛夫(Tomáš Mikolov)和Snap(Snapchat母公司)電腦科學家米奈(Shervin Minaee)等人所著的論文中,將語言模型的發展分成4階段:統計語言模型、神經語言模型、預訓練語言模型以及大型語言模型。
語言模型發展4階段一覽
| 年代 | 語言模型發展 | 模型與方法舉例 | 背後技術 | 用途 |
| 1990s | 統計語言模型 | n元模型 | 統計學、機率 | 協助解決特定的NLP任務 |
| 2013 | 神經語言模型 | word2vec | 詞向量、神經網絡 | 解決更廣泛的NLP任務 |
| 2018 | 預訓練語言模型 | BERT、GPT-1 | 上下文、預訓練、微調 | 能夠解決更多樣的NLP任務 |
| 2020 | 大型語言模型 | GPT-3、Claude | 透過規模達到湧現 | 通用地解決真實生活任務 |
| 整理:曾子軒。資料來源:Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., ... & Wen, J. R. (2023). A survey of large language models. arXiv preprint arXiv:2303.18223. | ||||
統計語言模型是什麼?
統計語言模型(Statistical Language Model)可說是語言模型的基礎,它試圖透過訓練資料,以「n元」(n-gram)模型,也就是計算詞彙與其後續詞彙出現的機率,用來預測詞彙何時出現。
舉例來說,「玉」後面時常接著「山」共同出現(co-occur),當語言模型被用來執行翻譯、語音識別等任務時,就會較容易預測出「玉山」,而不會貿然猜測「玉水」。「n元」模型不只能計算後一個詞彙,也有二元(bi-gram)、三元(tri-gram)等,一次看兩個字、三個字等方法。
不過,統計語言模型也有其限制,當訓練資料筆數增加,就有難以處理的稀疏性(sparsity)問題,也就是為了儲存資料,矩陣大小急速上升,帶動模型運算量以指數成長,另外還有無法考慮順序、沒有辦法涵蓋訓練資料以外情況的限制,遇上所謂「維度的詛咒」(curse of dimensionality)。
神經語言模型是什麼?
隨著深度學習進展,不管是傳統的回歸或者分類任務,還是處理圖像與文字,神經網絡(Neural Network)架構席捲一切。
從前饋神經網路(Feedforward Neural Network)開始,再到遞迴神經網絡(Recurrent Neural Network,RNN)、長短期記憶神經網絡(Long Short-Term Memory,LSTM),語言模型不再只能按照單一順序預測下個詞彙,而能夠更進一步捕捉到微妙字義。這也是神經語言模型(Neural Language Model)取代統計語言模型的時期。
2003年時,日後奪下圖靈獎的班吉歐(Yoshua Bengio)團隊提出神經機率語言模型(Neural Probabilistic Language Models),顛覆過往把詞彙一一對應到數值(one-hot representation)的表示方式,改把詞彙轉以分布式的表示方式(distributed representation)-詞向量(word vector)呈現,藉此成功捕捉到詞彙之間的相似性。
因為在向量空間中,每個詞彙都得到安放,神經語言模型成功克服維度詛咒,不用擔心稀疏性問題。也因為能夠輕易衡量相似性,因此翻譯不同文字、應對使用者的搜尋等任務,都能讓詞向量披掛上陣。
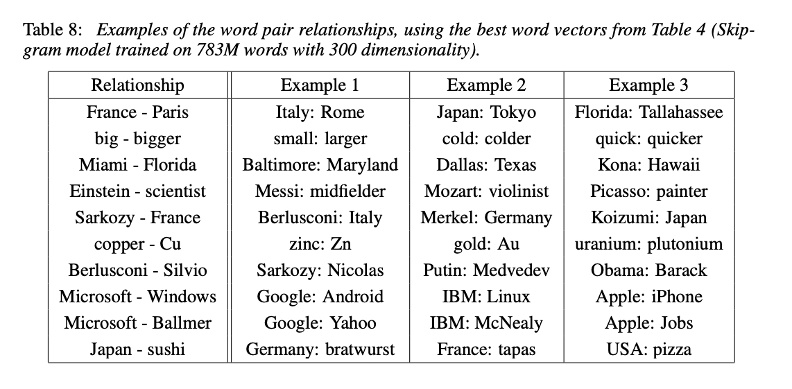
將時間快轉至2013年,米可洛夫和同事在班吉歐的基礎上,採用兩個新的框架,提出word2vec。word2vec同樣用向量衡量詞彙,並取一定的「窗口」(window size),用來預測在給定某個詞彙之後,其他詞彙出現的機率。因為不只有看離自己最近的詞,因此能夠克服「n元」(n-gram)方法的限制。
word2vec同時能夠掌握詞彙間句法(syntactic)和語義(semantic)上的相似程度,最直白能理解的例子是,「國王」的詞向量數值減去「男人」再加上「女人」後,得到的詞向量數值接近「皇后」。
日後也有學術研究者反其道而行,利用word2vec掌握詞彙之間距離的方式,量化文本之間潛在的歧視與偏見,例如現任Google DeepMind的研究科學家托加(Tolga Bolukbasi)的著作「男人之於電腦工程師就像女人之於家庭主婦」,就是以去除word2vec偏見為核心命題。

預訓練語言模型是什麼?
2017年,Google發表一篇至今仍廣受致敬的論文,介紹轉換器(Transformer)架構,開啟新的預訓練語言模型(Pre-Trained Language Model)時代。轉換器架構裡有著編碼器(encoder)和解碼器(decoder),不管輸入的是文字還是圖片或者影像,只要是序列(sequence)資料,都能夠經過編碼器轉成向量,也就是前面提過的詞向量、詞嵌入。
接著,透過自注意力(self-attention)機制,模型有辦法掌握輸入向量中不同詞彙的重要性,接續產出注意力權重(weight)的表示,在不同神經網絡層之間層層傳遞,最後再由解碼器輸出。
跟過往不同之處在於,使用者無需事先標記,只要拿現成資料,轉換器就能自行衡量輸入序列當中各個元素的價值,且因為有著注意力機制,即便詞彙之間相隔甚遠,模型也能掌控彼此之間的依賴關係,因此可以有效處理更長的序列。
值得一提的是,對比先前的遞迴神經網絡,轉換器架構的注意力機制運作方式,不用按照順序處理資料,這讓它適合平行運算(parallelization),不僅加快運算速度,還能夠處理長度更長的序列,這也讓黃仁勳的GPU帝國得以聳立。
就在發表轉換器架構隔年的2018年,OpenAI結合轉換器和非監督式學習發表首代GPT模型(Generative Pre-Training Transformer),其參數大小約為1.2億。
OpenAI解釋,它先是拿大量資料,以非監督方式訓練出轉換器模型,接著在第二階段以監督式,也就是標記好的資料微調模型,以便學習處理特定領域任務。之所以先以非監督式學習訓練模型,關鍵就在於成本,不用再把大量人力投注在清理資料、標記資料上。
其實,word2vec和其他詞嵌入技術也只需要前處理,同樣屬於非監督式學習,但轉換器架構在模型架構上作出改進,表現也因此得以提升。不過,OpenAI也補充,打造預訓練模型也有昂貴之處,尤其是在算力上的投資所費不貲。
Google科學家同樣以轉換器架構為基礎,同樣拿出有預訓練模型加持的「BERT」,推升語言模型處理問答、辨識實體等任務的能力,當時BERT基本款模型的參數大小為1.1億,BERT更大款模型的參數大小為3.4億。
大語言模型是什麼?
從預訓練模型,進展到大語言模型(Large Language Model,簡稱為LLM),其實是連續性的過程,而非如斷代史那樣有明確界限。學者便曾指出(2023),現有文獻中並沒有對於大型語言模型最小參數量的正式共識。
從規模上來看,韋恩、米可洛夫等人以百億(tens of billions)的參數大小(parameter size)為門檻,界定預訓練模型和大型語言模型的分野。當然,大型語言模型本質上就是預訓練模型,只是從能力來看,隨著模型規模提昇,諸多能力跟著湧現(emerge)。
舉例來說,提供簡單例子便能舉一反三的上下文學習(in-context learning)、提供指令就能按表操課甚至不用舉例的遵從指令(instruction following)以及把任務拆解的多步驟推理(multi-step reasoning),都是大語言模型相對於規模較小的預訓練模型,所湧現出的能力。
回望2018年發表的BERT和GPT-1,再對照今年7月META推出的LLaMA3.1、去年OpenAI公布的GPT-4,模型進展速度飛快,模型參數大小已從億等級,暴衝至千億甚至萬億等級,訓練資料量也從十億衝到兆級。
4種預訓練模型的大語言模型參數和訓練資料量(節選)
| 模型名稱 | 最大版本模型參數 | 公布年份 | 是否開源 | 訓練資料符元 |
| BERT | 3.4億 | 2018 | V | 137B |
| GPT-1 | 1.2億 | 2018 | V | 1.3B |
| GPT-4 | 17600億(未證實) | 2023 | 13T | |
| LLaMA3.1 | 4050億 | 2024 | V | 15T |
| 整理:曾子軒,挑選2018年和近兩年模型比較。資料來源:META、Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M., Socher, R., Amatriain, X., & Gao, J. (2024). Large language models: A survey. arXiv preprint arXiv:2402.06196. | ||||
在縮放定律(scaling law)的加持之下,在可見的短期未來,將會持續看到模型持續擴大,讀進更多訓練資料、增加模型參數量,以便突破能力前緣的努力。與此同時,回過頭來把模型縮小,但又不影響表現的小語言模型如GPT-4o mini、Gemma、Phi-3,也是發展方向。
最初的統計預言模型只能解決特定任務,隨著技術演進,大型語言模型已進化成可以處理各式任務,具有泛化(generalization)能力的通用模型。由LLM驅動的AI代理也準備上場,成為你我身旁的數位員工。
展望未來,科學家和科技巨頭們能否一路高歌猛進,通往通用人工智慧(AGI)的未來?大家都在看。



