
















最近美國社群平台Reddit上一位達人分享「用 Nano Banana 把自家狗狗做成公仔模型」指令,讓近期Google這個正式名稱為Gemini 2.5 Flash Image的圖像編輯模型持續人氣爆表!還讓ChatGPT 4o用戶紛紛跳船。到底這個AI模型如何註冊使用?免費付費?美國網友分享的最強公仔指令怎麼做?秒換背景、換衣服完成多輪對話圖片跟DIY繪本漫畫的神奇效果實測結果為何?優點與缺點?一文拆解。
Nano Banana是什麼?怎麼用?
近期幾週在AI評比平台LMArena上,排名第一的圖像編輯模型「Nano Banana」引起網友熱議,紛紛推測是哪家公司的大作。直到Google 26日發表最新圖像編輯模型Gemini 2.5 Flash Image時,才證實這就是傳說中的「Nano Banana」。
Gemini 2.5 Flash Image最大的特點,是在多次編輯照片後,仍能維持當中人物的長相。這讓使用者可以用自己的照片更換髮型、衣服、背景等,也不會因為AI重新生成圖像就「變了個人」認不出自己。
Nano Banana如何註冊使用?費用?
- 正式名稱為Gemini 2.5 Flash Image的Nano Banana目前完全免費提供。有兩種方式可以使用來編輯圖片:
用Gemini應用程式登入
- 1. 用 Google 帳號登入 Gemini (手機或網頁皆可)。網址:請點此
- 2.在對話框上傳你想編輯的圖片(寵物、人像或角色)。
- 3.下方點選「圖像」(Image Editing )以啟用 Nano Banana 功能
- 4. 在對話框中輸入你要執行的圖像變更:背景、角色姿態、造型等。
用Google AI Studio 方式登入
此外,在Google AI Studio中,也可選擇「Gemini 2.5 Flash Image Preview」,免費使用Nano Banana,以及其他運用此模型製作的應用程式,例如可生成相同人物的多張不同風格照片的「Past Forward」,以及可以用AI自動完成手繪圖像的「Gemini Co-Drawing」等。
Google AI Studio網址:請點此
實測1:公仔生成與微調指令教學
上週,一位Reddit用戶Echoing_Silence分享了他使用Nano Banana來為自家狗狗生成3D公仔圖像,立即引爆全球網友跟隨模仿。到底他的原初指令怎麼下?以下是中英文對照:
以下即是使用原版指令的原圖與結果對照圖:

微調建議
也可以自行調整主題與細節,比如改成「放在書桌上、配木質底座、旁邊擺迷你花瓶」等等。以下即是微調指令為「放置在書桌上,使用木質底座。書桌後面是窗戶」的實測結果。

實測2:更換人像背景
首先實測Gemini 2.5 Flash Image最重要的亮點,也就是維持人物一致性。針對一張在森林裡拿著一朵小花的年輕男性照片,輸入「將場景換成在海邊、衣服換成藍色T恤、手上換成拿著小螃蟹」指令後,其生成的結果確實有依指令更換場景、人物衣服和手上物品,並且,人物的長相與姿勢皆與原圖相同。

實測3:結合多張圖片
將多張圖片完美結合,也是Gemini 2.5 Flash Image強調的特點,例如合成兩個人的合照,或是讓模特拿著產品等。
實測提供一張年輕女性的照片,以及一杯飲料的照片,輸入「請讓圖一的人物手上拿著圖二的商品,並且露出開心的表情」指令,測試合成圖片與改變模特表情的效果。結果雖然模特長相不變,也確實有在手中拿著那杯飲料,但卻憑空多出了一隻手。

實測4:多輪對話編輯圖片,可換衣服
以往不少圖像模型的缺點是,每次生成都有細節不同,難以維持穩定品質,但Gemini 2.5 Flash Image相對沒有這個問題。如果想在Gemini 2.5 Flash Image生成的圖像中新增或刪除元素,可以在聊天室中多次傳送指令,其會延續過去成品,保留圖像中的元素,只修改指令中要求的特定部分。
實測使用一張背景為藍天的女性照片,依次要求AI將背景更改為百貨公司、讓二樓站滿人、將模特的衣服改成粉紅色,每次的成果都有確實依照指令,且不更動畫面中的其他元素,成品令人驚艷。


完整對話請見此連結。
實測5:自動完成手繪圖像
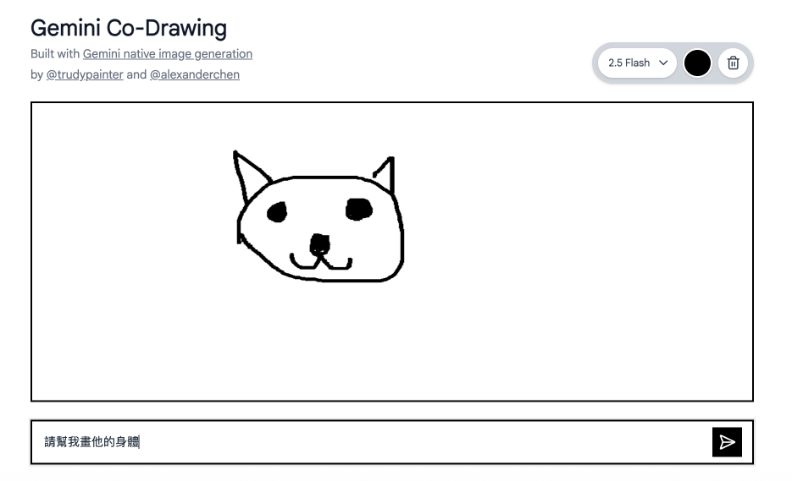
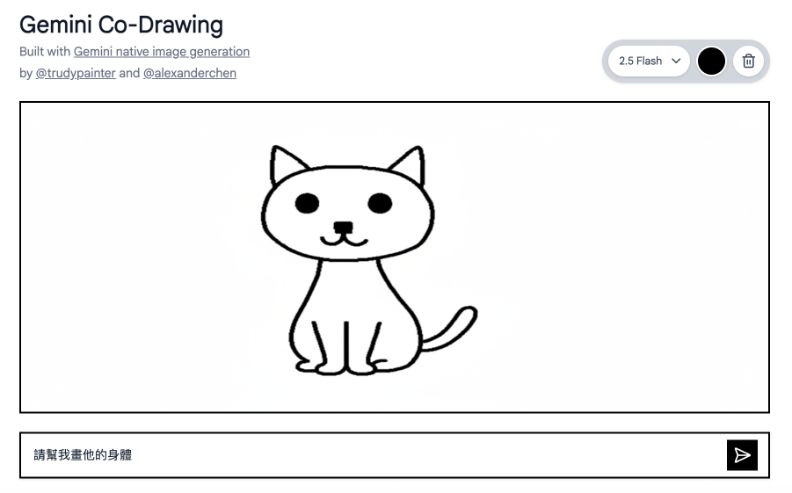
在Google AI Studio中,還有一些使用Gemini 2.5 Flash Image的延伸應用程式。例如Gemini Co-Drawing就是能讓AI自動完成手繪圖像的工具。這是Google為證明其具備生活常識,能根據常理生成圖像而開發的示範應用,可用於理解圖表、解決數學問題等方面。
實測手繪一隻貓咪的臉,並輸入指令「請幫我畫他的身體」後,AI就接著畫完整隻貓,並且沒有改動原先的筆觸太多。
實測結論:可用於繪本、漫畫等,需要維持角色的情境
整體而言,Gemini 2.5 Flash Image確實如其強調的特點,在維持人物一致性方面表現出色,克服了過去許多圖像生成模型無法用同一人物生成多張圖片的缺點,這項優勢未來可應用在生成繪本、多格漫畫,或甚至是影片等,需要用同一角色說故事的情境。不過,本次實測中也出現多了一隻手的人物,顯示AI生成人像的成果仍然不太穩定,需要調整指令多次測試。



