



















OpenAI的ChatGPT的圖像生成能力迎來重大突破,只要利用GPT-4o模型,簡單指令就能做出從吉卜力風格人物風格,到川普梗圖諷刺漫畫、設計選舉海報,甚至能夠在圖片中加上文字,不再是過往虛構的「AI文」。ChatGPT生成圖像有多強?能夠生成哪些風格?你還在用 Photoshop 修圖嗎?還是覺得AI生成的圖片總是缺乏細節、不夠精緻?現在,一切都將改變。《遠見》整理ChatGPT生成與編輯圖片的實用功能,帶你一次看。
本週二(3/25)OpenAI執行長奧特曼(Sam Altman),在直播中向全球ChatGPT使用者宣告,ChatGPT將支援原生圖像生成功能,使用者可以直接在ChatGPT內創造並編輯生成內容,「這是有史以來,我們發表過最有趣、最酷的東西。」
這是ChatGPT圖像生成能力的首次重大升級,也是本月稍早Google推出影像編輯功能、席捲AI社群以後,OpenAI的明快回應。從X(前推特)和臉書上的討論看來,OpenAI技高一籌。
ChatGPT圖像生成有哪些更新?
OpenAI指出,ChatGPT生成的圖像不僅美觀,而且實用,他們希望能夠讓更多人以更直觀且可控的利用AI創作圖像,而且不用切換到其他工具。
OpenAI表示,原生圖像生成功能開放給付費與免費用戶使用,接下來也預計將此功能開放給開發人員調用。
在直播和部落格文章裡,OpenAI特別強調ChatGPT生成圖像的幾項亮點:
◎ 維持一致性:過往利用AI生圖的痛點之一,在於當使用者想要微調內容時,AI生成的人物或者背景可能面目全非,對製作設計素材者來說並不夠實用,ChatGPT這波更新裡,讓不同張生成內容中能夠保持角色外觀的一致性。
◎ 理解更細緻的指令: ChatGPT能夠更精確地理解使用者提供的詳細圖像生成指令。
◎ 視覺風格重塑:無論是梵谷的星空,還是宮崎駿的動畫風格,ChatGPT都能夠將圖片或者照片,轉換成不同風格生成。
◎ 加上文字:能夠在圖像中生成更清晰、準確的文字。目前實測看來,加上中文字仍有不夠清楚的挑戰,且時常生成簡體字,但加上英文已經沒有問題。
◎ 圖像編輯:如果對於生成圖像不滿意,ChatGPT使用者可以圈選特定區域,再用文字溝通,ChatGPT便會重新微調生成內容。
◎ 透明圖層:生成具有透明背景的圖像,方便後續編輯和合成。
◎ 圖像輸入:除了請ChatGPT憑空生成圖像以外,也可以自己準備素材上傳至ChatGPT,且可以一次上傳多張圖片或者照片。
◎ 多輪對話:因為ChatGPT能夠記得的上下文變多,生成圖像時可以來回和ChatGPT溝通,微調生成圖案內容,它也不會輕易「忘記」。
ChatGPT圖像生成能力,十六種實測揭露真實效果
ChatGPT生圖實測:生成圖片後微調
首先測試利用ChatGPT從零開始生成圖像。
第一次所下的指令為「請生成一張某個人正在寫程式的圖像,寫實風格。」生成內容後再測試微調結果。
第二次所下的指令為「請調整:a. 不喜歡dark mode,請改成light mode,b. 眼鏡換成金色邊框、圓框,c. 桌上放一杯水。」
以下為實測結果:

ChatGPT生圖實測:生成圖片後調整風格
接著測試ChatGPT調整風格的能力。
第一次所下的指令為「請生成一張川普(trump)跟普丁(putin)身穿中國傳統服飾準備拜堂的寫實圖片。」生成內容後再測試風格轉換。
第二次所下的指令為「非常好,可否用同樣構圖,改編成一張傳統報紙上常常看到的諷刺漫畫,」得到第二張圖片後再補充要求補上細節:「在這張漫畫底下加上烏克蘭總統澤倫斯基,被兩人踩在腳下。」
以下為實測結果:

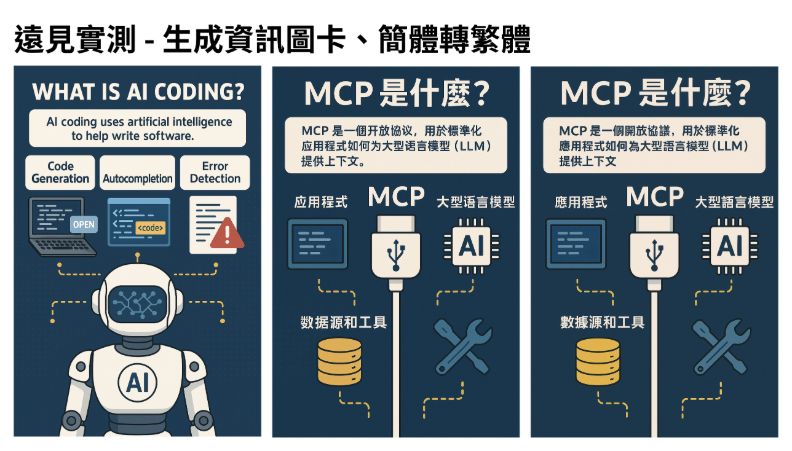
ChatGPT生圖實測:生成資訊圖卡
測試ChatGPT能否生成社群上常見的資訊圖卡/圖表。
第一次所下的指令為「請你生成一張infographic 解釋 AI Coding (AI寫程式)是什麼。」
接著想測試若事先準備內容,ChatGPT能否吸收後製作圖卡。
第二次所下的指令為「請你生成一張infographic 解釋 MCP (model context protocol )是什麼,請用中文。」
與此同時,也在指令中附上Claude官網中介紹MCP的文字:
生成的圖卡中文字都是簡體,因此再調整:「可以用繁體字嗎?」
以下為實測結果:
ChatGPT生圖實測:生成資訊圖卡並加圖片
確認ChatGPT生成圖卡的能力後,接著想製作更加複雜的圖卡。這次準備昨日(3/26)吳恩達公開演講和會後受訪內容報導全文給ChatGPT,指令為「請參考下方文字,消化吸收以後,產出infographic,整理重點。」
ChatGPT並未直接生成圖卡,而是先以文字整理大綱,和使用者討論是否符合需求,並且在對話結尾提問:「如需我幫忙設計實際的 infographic 圖稿(中英雙語或中英混排、橫版/直版、社群用圖等),也可以再告訴我你預計的使用場景或平台,我可以進一步製作圖像。是否需要?」
回答「你的提案可以。中文就好,橫版,社群用途」以後,ChatGPT產出第一版圖卡(下圖左上)。
為了讓圖卡更寫實,使用者上傳實際拍攝的吳恩達照片(下圖左下),指令為「這是吳恩達的照片,可否將其放入infographic當中。」
ChatGPT照做後產出第二版圖卡(下圖下排中間)。因為字數太多,中文呈現效果差,因此再要求生成英文版,「請你再生成一張英文版的,」產出第三版圖卡(下圖右下)。
最後測試調整內容的能力,指令為「能否製作四張圖卡,一張強調一個大的重點?」雖然只產出一張圖片(下圖右上),但若繼續對話應可完整產出四張。

ChatGPT生圖實測:細修數字
測試ChatGPT調整文字的能力。
上傳照片後,所下的指令為「請把圖中的2024改成2025。」
以下為實測結果:

ChatGPT生圖實測:細修中文字
測試ChatGPT調整中文字的能力。
上傳照片後,所下的指令為「幫我把李雅英改成李珠珢。」
以下為實測結果:

ChatGPT生圖實測:微調圖片細節 - 衣服
測試ChatGPT調整圖片中細節的能力。
上傳照片後,所下的指令為「請把圖上人物所穿的衣物變成白色系。」
以下為實測結果:

ChatGPT生圖實測:生成微調圖片 - 人物表情
測試ChatGPT調整圖片中細節的能力。
第一次所下指令為「幫我生成一張照片,內容是幾個台灣記者在開會討論題目,有張小白板上面有寫字,討論內容是下期封面故事發想,候選題目有AI應用、VTuber普及和高齡化。」
產出內容後,再要求微調:「調整表情,讓大家看起來在吵架,拿筆的改成摔筆。」
以下為實測結果:

ChatGPT生圖實測:生成內容 - 四格漫畫
測試ChatGPT生成漫畫的能力。
第一次所下的指令為「請你幫生成一張四格漫畫,主題是員工跟老闆吵架,越好笑越好。」ChatGPT產出一版無字幕的漫畫後,再要求調整。
指令為「請加上中文字(類似字幕或者旁白,漫畫都會有),要不然好像看不太出來笑點在哪。」
ChatGPT表示,會依格子順序附上對白與旁白說明,風格偏向日常荒謬感,接著提供腳本,確認無誤後產生第二版漫畫。
以下為實測結果:

ChatGPT生圖實測:生成內容 - 按照原圖產生四格漫畫
測試ChatGPT生成漫畫的能力。
所下的指令為「請將這張圖片轉換成一張四格漫畫,要包含中文字,主題是去森林圖書館冒險。」
以下為實測結果:

ChatGPT生圖實測:合成照片 - 宣傳活動
測試ChatGPT合成圖像的能力。
一共下了兩次指令,產出兩張圖,分別是「請讓左邊的男生幫忙右邊的國際動漫節活動打廣告,但要維持第一張照片的佈局」以及「請再做另一個版本,讓左邊的男生加到右邊的戶外活動中。」
以下為實測結果:

ChatGPT生圖實測:合成照片並調整角度
測試ChatGPT合成圖像的能力。
一共下了兩次指令,產出兩張圖,分別是「請把右邊的女生加在左邊那張圖片,看起來自然一點」以及「換個版本,請把左邊的男生加到右邊那張圖片,讓那個女生的視線看起來在看他,但要調整角度才自然。」
以下為實測結果:

ChatGPT生圖實測:合成照片之二
測試ChatGPT合成圖像的能力。
指令為「請把兩張圖加在一起,讓兩個人看起來在對談。」
以下為實測結果:

ChatGPT生圖實測:調整風格、加字、去背
測試ChatGPT調整風格與去背能力。
上傳照片後,所下的指令為「把這張圖改製成選舉海報風格,加上『懇請支持1號薑餅人』等相關標語。」
接下來的指令為「可以再改變成3D模型嗎?一樣是選舉海報風格,但裡面的玩偶變成3D。」得到3D模型風格的圖像。
再往後的指令為「可以再給我一版,這次做成透明圖層嗎?我要到別的地方編輯」並得到去背圖片。
以下為實測結果:

ChatGPT生圖實測:吉卜力風格與多輪對話
測試ChatGPT調整風格與多輪對話的能力。
上傳照片後,所下的指令為「請把這張照片變成吉卜力風格。」
接著再次調整風格:「調整成像是真人model?」因為髮色與原來的紫色不符,因此再要求調整:「頭髮可以保留成原本的紫色嗎?」
以下為實測結果:

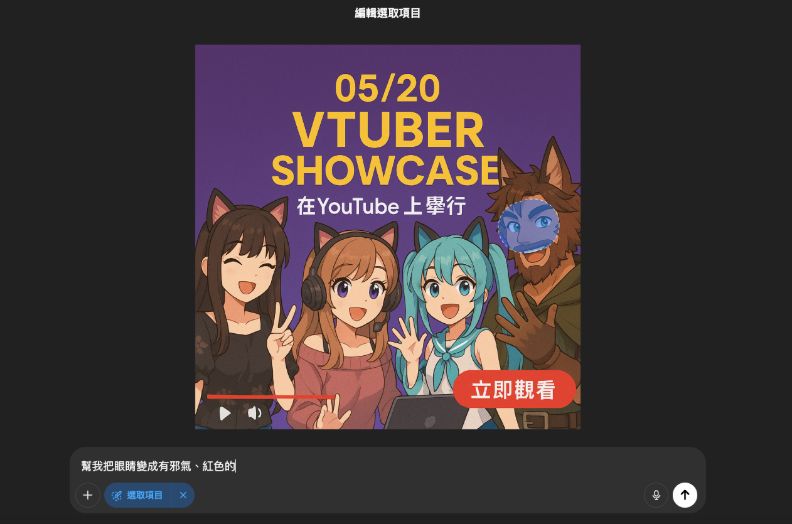
ChatGPT生圖實測:生成內容並加上更多人物、微調細節
測試ChatGPT生成素材、調整內容與多輪對話的能力。
指令為「請幫我產生一張新的宣傳圖素材,文字內容請參考以下:『05/20 舉辦VTuber 研討會,在YouTube上舉行。』圖片部分,希望看起來有VTuber在YouTube上直播」
因為文字部分不夠醒目,因此要求調整:「不錯。希望熱鬧一點,然後要有好的標語,不要那麼raw,例如取個好的活動名稱再新增call to action。」
接下來再改動兩次:「不錯!換成三個」以及「加上男V,獸人風格。」
最後利用ChatGPT編輯圖片的功能(如下圖),將獸人男V的眼睛圈選後,要求ChatGPT「幫我把眼睛變成有邪氣、紅色的。」得到最終成品。
以下為實測結果:

ChatGPT圖像生成能力升級有何挑戰?
雖然GPT─4o在圖像生成上有所升級,整體畫質、細節處理都有顯著提升,但在處理複雜結構和精細編輯時仍有不足之處。
◎ 裁切問題:對於較長的圖片(如海報),模型有時會裁切得太緊,特別是底部容易被截掉。
◎ 幻覺問題:像文字生成一樣,圖像生成也可能憑空捏造內容,特別是當提示資訊不足時。
◎ 難以處理過多細節:當圖片需要包含 10─20 個以上的獨立概念(如完整的元素週期表),模型容易出錯。
◎ 繪製精確圖表的能力不足:生成精確的圖表效果通常不佳,例如x軸、y軸座標切分方式有誤,或者圖表上的資料點位置不精確。
◎ 多語言文字渲染問題:對於非拉丁字母(如中文、日文),模型可能會產生錯誤字形,或生成完全不存在的字。
◎ 編輯精準度不足:如果要求修改圖像的特定部分(如修正拼字錯誤),模型可能會影響到其他區域,甚至引入新的錯誤。
◎ 人臉一致性問題:當用戶上傳照片並要求修改,模型有時無法保持人臉一致性,但這個問題預計很快會修復。
◎ 細小文字與密集資訊:模型在處理細小字體或大量密集資訊時,容易模糊或錯誤渲染。
如同奧特曼所說,ChatGPT的更新,可以賦能給不擅長繪圖與設計的平凡你我,讓人們能夠將想像力化為現實,創造出過往不敢奢望的「內容」。不過,這樣的內容是否屬於創作,又會對長久以來,爭議頗大的版權議題帶來哪些全新挑戰,都是美國、台灣甚至全世界能密切關注的問題。



