







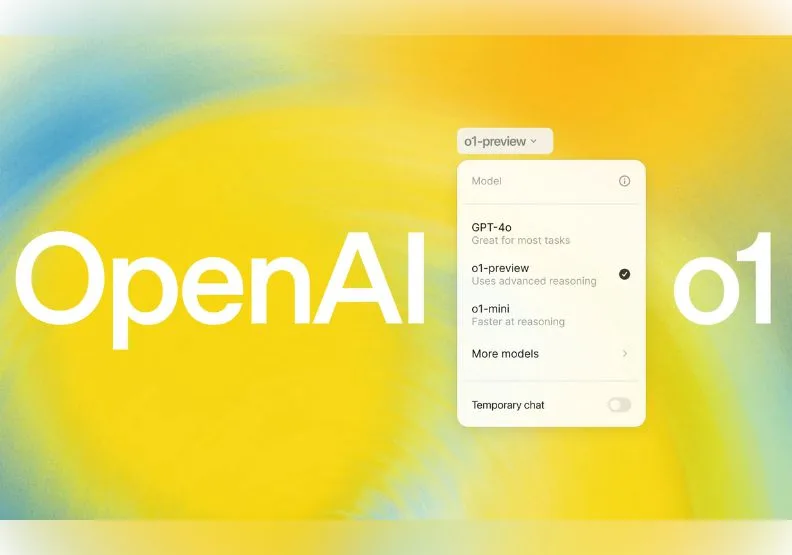
OpenAI除ChatGPT,上週推出新系列模型,這個OpenAI o1預覽版,堪稱推理能力相當博士生,能花時間「思考」後解決複雜的任務。不過,針對一般人常用的情境而言,OpenAI o1會是最好選擇?或是使用相對快速的GPT-4o就夠了呢?本文實測了4個日常使用情境,並比較OpenAI o1和GPT-4o的差異。
OpenAI o1是什麼?
OpenAI 12日發布最新AI模型OpenAI o1的預覽版(OpenAI o1-preview),強調在回答問題之前,會先經過一連串的思考,以解決複雜和需要推理的任務。OpenAI表示,此模型在數學、程式方面表現出色,在國際數學奧林匹亞(IMO)的資格考試中,GPT-4o只正確解決了13%的問題,而OpenAI o1的得分則為83%。
目前,ChatGPT的Plus和Team方案的付費會員,可以使用OpenAI o1-preview和處理速度較快的小模型o1-mini。使用限制為每週30則o1-preview訊息、50則o1-mini訊息。接下來會陸續開放Enterprise和Edu方案的會員使用。
以下測試皆使用OpenAI o1-preview和GPT-4o進行比較。
實測1:用Python寫小遊戲
首先測試OpenAI o1擅長的程式問題,要求OpenAI o1和GPT-4o用Python寫一個賽車遊戲,並加上規則和計分的要求,例如要每兩秒提升一次遊戲速度,以及躲避一個障礙物加10分等。將AI生成的程式碼貼進Visual Studio Code中執行後發現,兩者皆能完整達成指令要求,不過可能是由於指令不夠複雜,OpenAI o1在此沒有特別的優勢。
要求OpenAI o1用python寫賽車遊戲。錄製自Visual Studio Code使用畫面
完整對話見此連結。
要求GPT-4o用python寫賽車遊戲。錄製自Visual Studio Code使用畫面
完整對話見此連結。
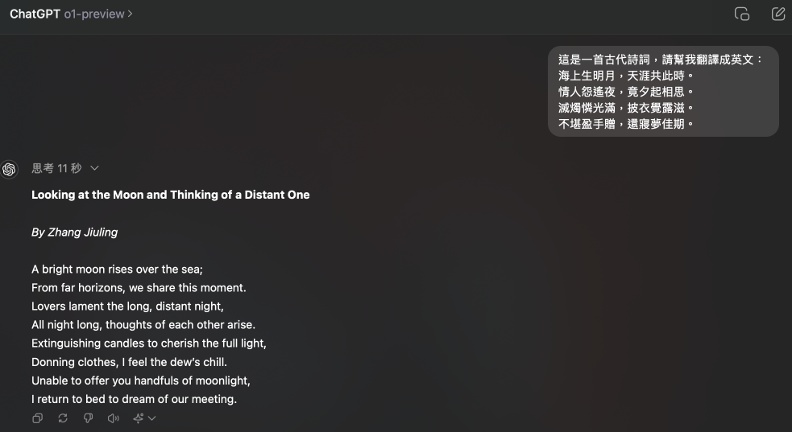
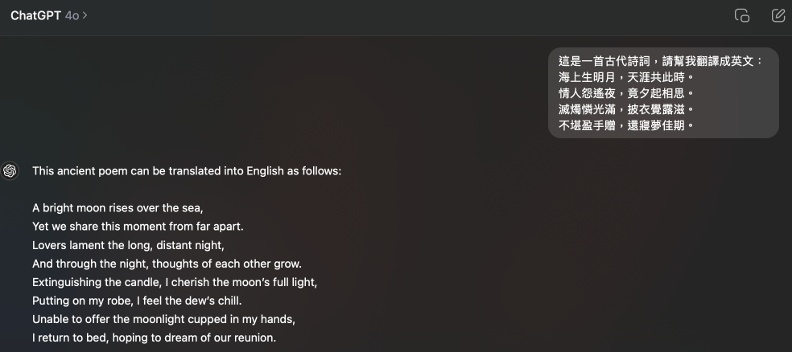
實測2:將唐詩翻譯成英文
要求OpenAI o1和GPT-4o將唐朝詩人張九齡的詩《望月懷遠》翻譯成英文,測試其是否能準確理解古文含義。結果發現,兩者皆有正確理解詩詞內容,不過GPT-4o的描寫較為細緻,OpenAI o1的文字則較簡單。
例如最後一句「還寢夢佳期」,GPT-o1翻譯成「I return to bed to dream of our meeting.」,GPT-4o則翻譯為「I return to bed, hoping to dream of our reunion.」。相較之下,GPT-4o的翻譯較有意境,也較有情感。
實測3:摘要長文重點與延伸討論問題
將一篇英文論文輸入進OpenAI o1和GPT-4o,並要求其用中文整理重點,並提供三個有深度的討論問題。由於OpenAI o1目前無法上傳檔案,因此本次實測是將完整論文文字貼進對話框;使用GPT-4o時則是直接上傳檔案。
結果發現,兩者整理出的論文重點大致相同,但在延伸討論問題方面,OpenAI o1提供的問題較有深度。例如OpenAI o1提出的第三題:「作者提出的模型主要基於靜態影像的分析。在影片和互動式媒體日益重要的今天,如何擴展或調整這個模型以適用於動態影像和多媒體內容的視覺框架分析?」其跳脫原文背景,將理論套用在當代狀況討論。


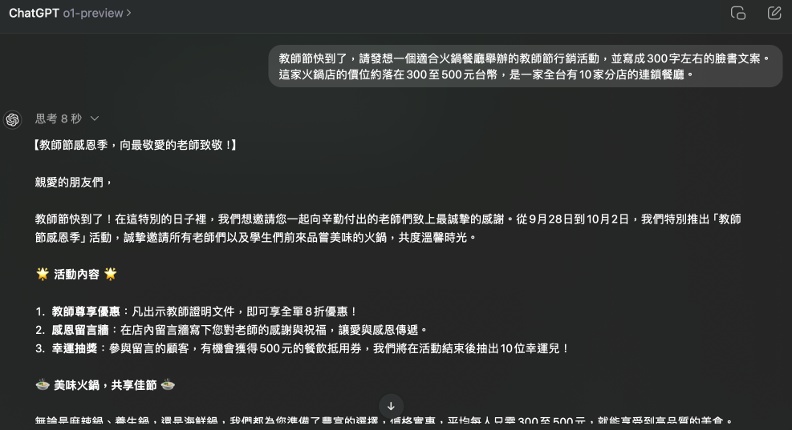
實測4:撰寫社群媒體文案
要求OpenAI o1和GPT-4o發想行銷企劃,並將其寫成臉書社群文案。比較兩者生成的結果,發現兩者都有提出具體的活動方案,也有使用emoji強調重點。不過,針對原先指令中「300字文案」的要求,OpenAI o1生成的文案為468字、GPT-4o則為303字,因此只有GPT-4o較為準確地達成要求。
完整對話見此連結。

完整對話見此連結。
OpenAI o1 vs GPT-4o比較
彙整上述4項實測的優缺點比較表格。整體而言,大多數日常任務使用GPT-4o就能順利且快速地達成要求,如果是與寫作和翻譯有關的任務,GPT-4o的表現甚至更好;不過,如果是需要較多延伸思考的任務,則OpenAI o1的表現較佳。
另外,以下表格僅代表本次實測結果,實際情形可能因為指令不同或AI的隨機性而有所差異。
| OpenAI o1 | GPT-4o | |
|---|---|---|
| 用Python寫小遊戲 | 程式碼能順利執行,也能完整達成要求。 | 程式碼能順利執行,也能完整達成要求。 |
| 將唐詩翻譯成英文 | 能正確理解原文內容,但翻譯文字較簡單。 | 能正確理解原文內容,但翻譯文字較細緻。(勝) |
| 摘要長文重點與延伸討論問題 | 能完整整理重點,且延伸問題較有深度。(勝) | 能完整整理重點,但延伸問題較簡單。 |
| 撰寫社群媒體文案 | 能正確達成目標,但字數超出要求。 | 能正確達成目標,且字數精準達成要求。(勝) |
| 資料來源:《遠見》記者實測|表格整理:郭宇璇 | ||



