由OpenAI開發出的ChatGPT席捲全球,它如何快速註冊使用?背後原理為何?想一小時搞通指令,竟有AI大師吳恩達的免費線上課程可學?另外,ChatGPT在台灣也一樣神?國內企業與個人第一波使用經驗談又如何?《遠見》一文完整更新。
ChatGPT已是2023年最夯話題,最近根據OpenAI團隊的T.E.D.演講展示,它下一波功能將更加自動化!如此進步速度飛猛的生成式AI工具,該怎麼掌握?其實現在才開始學,還來得及,更有大師免費線上課程,可讓你一次搞通指令。台灣企業與個人,則已經有首波使用者經驗談。到底它有多神?如何入門上手?以下請見全解析。
ChatGPT是什麼?怎麼註冊?
ChatGPT的開發者是一家專精於人工智慧的組織OpenAI,OpenAI曾推出輸入文字便能輸出圖像的DALL-E、給定音樂風格和歌詞就可以產出音樂作品的Jukebox,以及近年陸續公布的GPT模型,包含2020年推出時震撼全球的語言模型GPT-3,以及今年進一步更新的GPT-4!它威力更為強大,能夠在美國律師考試拿下高分,回答起奧林匹亞與美國大學預修課程的試題,也絲毫不見遲滯之感。
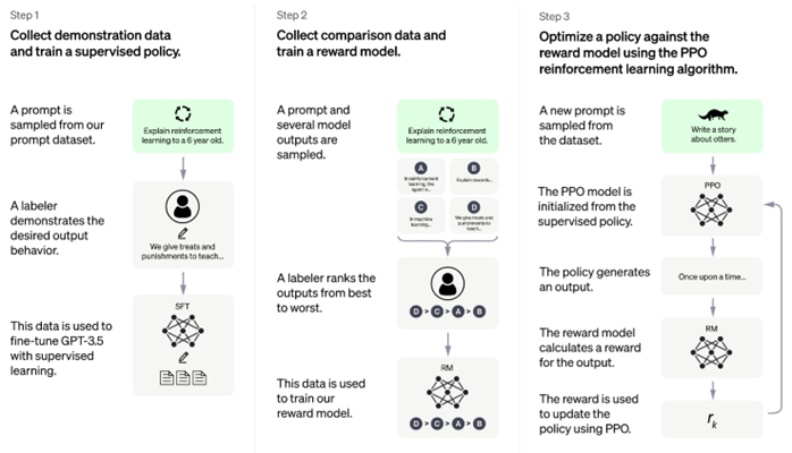
根據OpenAI的介紹,ChatGPT和先前曾推出的「打電動機器人」OpenAI Five一樣,都是透過由人類提供回饋的增強學習(reinforcement learning)訓練而成。增強學習的原理類似小朋友在玩電動遊戲,即使在場沒有成年人指導,幼童仍可以在不斷試錯當中,藉著每次挑戰所獲得的正向與負向回饋,找到能夠通關的策略。
訓練ChatGPT時便是仿照上述概念,OpenAI先請模型的訓練者們同時扮演使用者和人工智慧助手(即現在的ChatGPT)的角色,創造一定數量的數據,讓機器認識到對話的基本策略。接著,為了讓機器學到較佳對話內容與模式,訓練者會扮演使用者向機器擔任的人工智慧助手發話,此時訓練者會提供建議幫助機器撰寫回答。
為了讓機器「學習」,訓練者會擷取機器撰寫的不同語句,接著「告訴」機器回答內容的品質高低。這些線索有如「小朋友齊打交」的正向與負向回饋,機器可以藉此改善產出,並回頭更新其產生回答的策略,就這樣一步一步的離成品邁進。
為何ChatGPT如此厲害?
2016、2017年,AlphaGo接連擊敗圍棋名宿李世乭與柯潔,引發世人們熱議,然而,那畢竟是用途相對狹隘的弱人工智慧(weak AI),相較於在圍棋界獨孤求敗的AlphaGo,ChatGPT的應用場域顯得貼近生活,離泛用、接近人類的強人工智慧(strong AI)更進一步。
不過,ChatGPT仍屬於弱人工智慧的範疇,它的設計目標是模仿人類的對話,背後的運作原理與人類的邏輯推理不同,而是從預先訓練的資料中找尋能夠對應的素材,多番拼湊後產生回答。但是,對一般人來說,機器能夠如此流利的和人們交談,就已經足夠驚人。
ChatGPT的優異表現,很大部分要歸功於它所站立於上的巨人肩膀,也就是GPT-3。2018年,OpenAI發表論文,主要在討論如利用所謂「通用預訓練(generative pre-training,簡稱為GPT)」改善模型對於語言的理解,這個方法成功克服了當時機器學習研究者的痛點。
對投身人工智慧領域的產學界人士來說,即使技法再精妙、運算資源再豐沛,還是必須投入人力標注資料。舉例來說,在訓練機器判斷醫療影像時,想讓機器向醫生「學習」何謂罹患疾病,就必須讓機器知道每張照片對應到的標籤是陽姓或者陰性。
然而,若要拜託醫師花時間逐一標記影像,必然耗費巨大的人力成本。不只是影像辨識,其他領域亦然,機器生成的文字品質如何改進?人工智慧給人資的履歷篩選建議會不會有遺珠?這些都仰賴人類實際的回饋。
GPT厲害在它能夠基於無監督(unsupervised,指沒有標籤)的數據,建立起通用的語言模型,接著再針對有監督(supervised,指有標籤)的特定任務逐步微調,如此一來,便成功通過當時科學家遇上的瓶頸。
當然,使用無監督的數據生成模型說來容易,但實務上的挑戰甚巨,因為訓練模型需要大的運算能力,這意味著燃燒資本。就第一代GPT模型來說,預訓練的數據量達到約5GB,使用到的參數接近1.2億。隔年(2019)OpenAI發表GPT-2,預訓練的數據量暴漲,直接衝高到40GB,使用到的參數更是來到15億。OpenAI並沒有停下腳步,在2020年又釋出了GPT-3,這次的數據量翻了千倍,達到45TB,而參數量也升級到1,750億。
隔了3年,OpenAI在今年3月發表GPT-4,但沒有公布模型架構、參數細節、訓練過程,因此遭到外界抨擊,因為OpenAI的成果受益於其他研究機構和企業的開源,包含谷歌、臉書、學術團體等。人工智慧領域的大師楊立昆便指出,OpenAI已經從專注於研究的實驗室,轉變為開發產品、替微軟服務的單位,其保密做法更無法替世界帶來技術上的價值。
不看模型的參數數量,改看ChatGPT對話長度的token數,這個數字能夠反映出ChatGPT對話的上限,若超過此限制,它會忘記交談內容、失去脈絡。GPT-4出現後,系統能夠接受的token數量從4000躍升到了3萬2000,足足有八倍之多,這將大幅提升應用上的可能性;不過,現在OpenAI僅開放8000多個token的版本供人使用。
OpenAI並沒有公布訓練GPT模型所投入的資金。但就深度學習企業Lambda Labs的首席科學家推測,若是利用最便宜的雲端運算服務訓練GPT-3模型,需要花上至少460萬美元、耗時355年才能訓練完成。
怎麼使用ChatGPT一下就上手?
使用ChatGPT的時候,可以給它簡單的問句,例如問它應該選擇愛情還是麵包,但也有更系統化的做法,讓你得到的答案更實用、更精煉。在使用ChatGPT時,可以使用模板(template)或者框架(framework),重點是要將自己的提示詞拆解為數個部分:
●背景:簡介你即將請ChatGPT執行任務的背景,例如你的身分、正在跟誰協作。
●任務:具體來說,你希望ChatGPT幫你完成什麼事?是針對某個議題提供想法,或者是從一段文字中尋找重點。
●脈絡:你可以告訴ChatGPT關於任務的脈絡,例如以翻譯來說,可能有些特定的用詞,或者是這篇翻譯和某起事件有關;另外,若有先備知識,也要先提供給ChatGPT。
●限制與要求:若針對ChatGPT的產出有些要求,請記得提出,例如回覆內容的長度不要超過200字,或者是希望它用專業譯者的筆法寫作;有特別提出語調、風格,對於產出品質會有很大幫助。
除了參考上述在下指令時的注意事項以外,也有幾個實用技巧,包含請ChatGPT扮演特定專業角色、在LINE中串接ChatGPT、使用ChatGPT的擴充功能等。
一小時學ChatGPT指令的大師課:吳恩達釋出免費線上課程教什麼?
除了應用端,有意使用GPT模型的API開發新服務的人,也有課程可以學習。另一位人工智慧界的巨擘吳恩達,近期在自家平台Deeplearning.AI上和OpenAI的富爾福德(Isa Fulford),共同推出時長為1小時的線上課程,向工程師教授如何掌握提示工程(Prompt Engineering)。免費又大師傳授,同時他們放下專家身段,手把手從基礎教導,有心者不容錯過。
這堂課中,兩位授課教師會帶學員利用大語言模型打造服務,換句話說,就是利用OpenAI累積已久的模型實力,讓開發者們透過串接API,創造各式微型的新應用。很多過往由人類親自出手的任務,如今都可以找到機器代勞,例如學術研究常見的資料標記,或者是媒體工作者日常工作中的資料摘要等。
台灣企業與個人使用生成式AI第一手經驗談
ChatGPT在各界媒體與專家口中已快成「神器」,但真的實用嗎?包括Midjourney這類生成式AI工具在內,到底在台灣企業與個人實測間,引起多大波瀾?以下訪自國內眾多企業與個人的系列報導,值得深入了解:
ChatGPT有何隱憂?
ChatGPT開疆闢土的速度之快,也讓人開始擔憂人工智慧的迅捷發展,例如馬斯克等人便曾呼籲應該暫停開發大過GPT-4模型的人工智慧系統,引發社會各界激辯。儘管吳恩達反對停止人工智慧領域的研發工作,但他也承認,現有的AI的確有些待克服的問題,包含演算法帶有偏見、AI決策時的公平性有疑慮、權力集中於少數科技巨頭等。
事實上,ChatGPT的落地,雖然增進許多人的工作效率,但也為社會帶來了不少問題。從最直觀的應用來看,學生很有可能利用ChatGPT代寫作業,或者抄襲剽竊前人的著作,因此世界各地有眾多學校明令禁用ChatGPT。
另外,ChatGPT也有被用來生產大量虛假訊息的可能性,因為ChatGPT產出的文字可讀性和邏輯都達到一定標準,若是利用其編造似是而非的內容再到處傳散,很有可能造成社會動盪,包含釣魚信件的文字撰寫、YouTube上的投資誘騙影音、LINE的詐騙機器人等,都是ChatGPT能夠用來作惡的範例。
除了擔心老師們以後再也無法分辨作業是誰的產出之外,已經出現了人工智慧技術壟斷的相關討論。無論是Google的BERT,或者是OpenAI的GPT,不僅頂尖科學家要投入心血,企業更要挹注大筆資源,才能打造出厲害的模型。臉書、微軟、谷歌目前可說是大語言模型的領頭羊,亞馬遜、阿里巴巴、百度等也在努力趕上。雖然也有開源的大語言模型,但考量訓練成本與消耗算力,很難跟企業傾全力挹注的模型相提並論。
人工智慧的發展是個富者愈富、貧者愈貧的世界。當OpenAI開放ChatGPT讓眾人使用時,可以從人們的踴躍試用中得到更多回饋,進而改進其模型,而機器學習領域的評斷標準直接而殘酷,只有表現好的模型才有話語權,這又回頭仰賴企業的資源,因此直到今日,能夠開發出此類巨型語言模型的企業屈指可數。
就像科技作家「演算法決定世界」的預言一樣,人工智慧也把持在少數企業手中。這會為我們的生活帶來什麼樣的影響?是否會出現科幻小說當中的常見情節,日後人類生活會被少數科技精英與機器所主宰?我們必須關注人工智慧發展中的壟斷問題。