








各家AI公司搶搭「AI代理」(AI Agent)熱潮,陸續推出深度研究功能。馬斯克(Elon Musk)的AI公司「xAI」上週發表最新AI模型Grok 3,推出深度研究功能「DeepSearch」;AI搜尋引擎Perplexity近期也推出類似的「Deep Research」,兩者皆可免費體驗。此外,OpenAI早在本月初就推出此功能,25日起開放Plus訂戶使用。本文實測了這三個深度研究工具,其中兩者曾被黃仁勳欽點愛用,另一為對照組。看看他們的表現如何?各自有什麼特色?
Grok是什麼?Deep search怎麼用?
Grok是特斯拉創辦人馬斯克引領的xAI團隊所開發的生成式AI模型。2月18日,馬斯克帶領旗下的xAI正式發表最新一代模型Grok 3,其中也有Deep Search功能。使用方式很簡單,就是點入Grok3官網,點選對話平台上的「Deep Search」功能即可使用。目前免費用戶也能使用。
Grok官網網址:https://x.ai/
This is it: The world’s smartest AI, Grok 3, now available for free (until our servers melt).
— xAI (@xai) February 20, 2025
Try Grok 3 now: https://t.co/Tj0afLoxEz
X Premium+ and SuperGrok users will have increased access to Grok 3, in addition to early access to advanced features like Voice Mode pic.twitter.com/YgKavSCiWr
Perplexity是什麼?Deep Research怎麼用?
Perplexity是新創公司Perplexity於2022年12月推出的AI搜尋引擎,可以根據使用者的問題,上網搜尋資料後整理成短文。14日,Perplexity推出「Deep Research」功能,回答問題前會先搜尋數十個來源,再將其整理成架構完整的研究報告。
目前Perplexity的免費用戶,每天可使用五次Pro功能,除了Deep Research之外,還可使用DeepSeek和OpenAI的最新推理模型R1和o3-mini。
ChatGPT的deep research怎麼用?
OpenAI 2日推出ChatGPT的deep research功能,最初僅開放給每個月200美元的ChatGPT Pro方案會員使用,25日起擴大至Plus、Team、Enterprise和Edu方案的會員,每個月有10次的使用額度,Pro會員的額度則由100次增加至120次。
要使用deep research功能,只要在送出問題前選取「深入研究」按鈕即可。
以下針對Grok 3、Perplexity和ChatGPT的深入研究功能進行三項實測,並比較其回答結果。
實測1:AI發展時間軸
第一項實測想了解AI整理歷史時間軸的能力,輸入的指令為「請幫我整理近20年AI發展的時間軸,分為三個時期,一個時期標記出三個關鍵事件」。
【Grok 3】
Grok在生成研究報告時,會先列出思考流程,並統整參考來源,之後才開始生成報告。研究報告可分為「關鍵要點」和「詳細報告」兩部分,前者會先簡短概述內容重點,後者則是從背景說明開始,詳細講解每個分期,針對關鍵事件也附上表格。報告最後還列出「關鍵引用」,讓使用者可以優先參考最重要的來源。
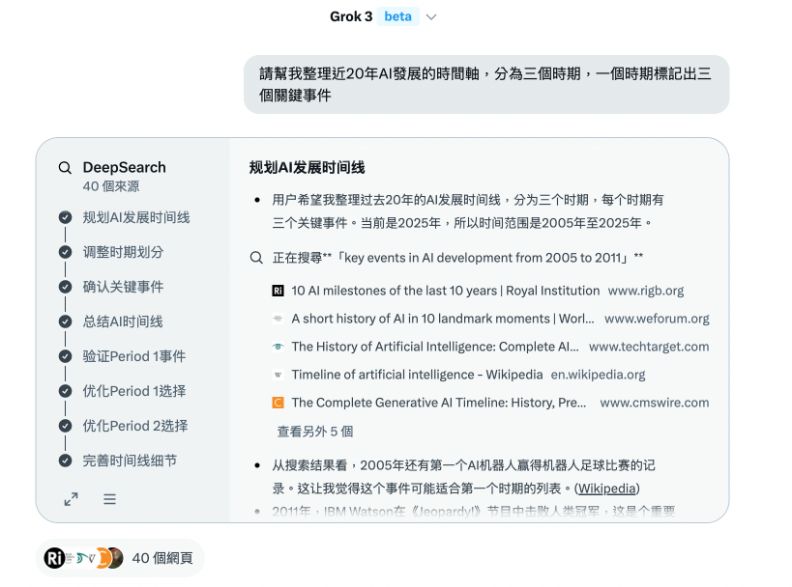


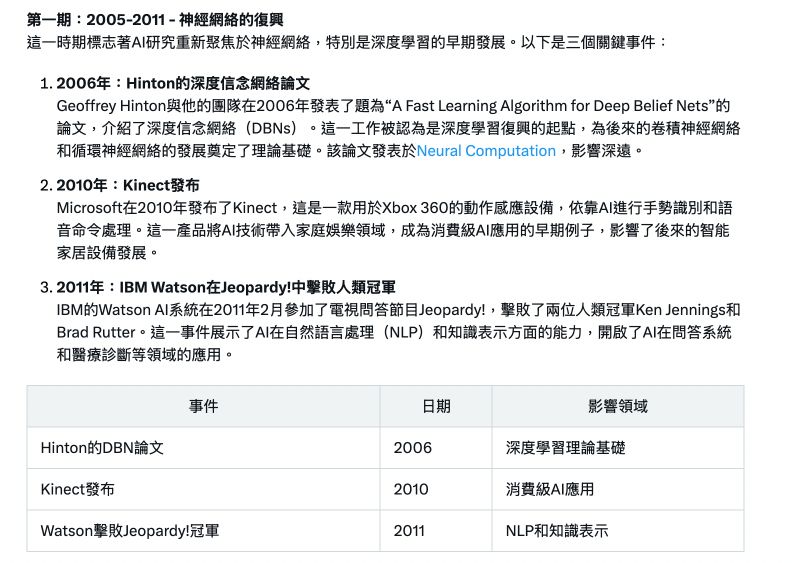
完整對話請見此連結。
【Perplexity】
Perplexity也是在回答的最上方列出參考來源和思考過程,再進入報告正題。其報告架構分為前言、三個時期說明和結論,其在每個時期列出三個特色,一個特色中提及數個事件,與指令所要求的「標記三個關鍵事件」不符。此外,其以純文字形式呈現報告,沒有使用表格整理重點。



完整對話請見此連結。
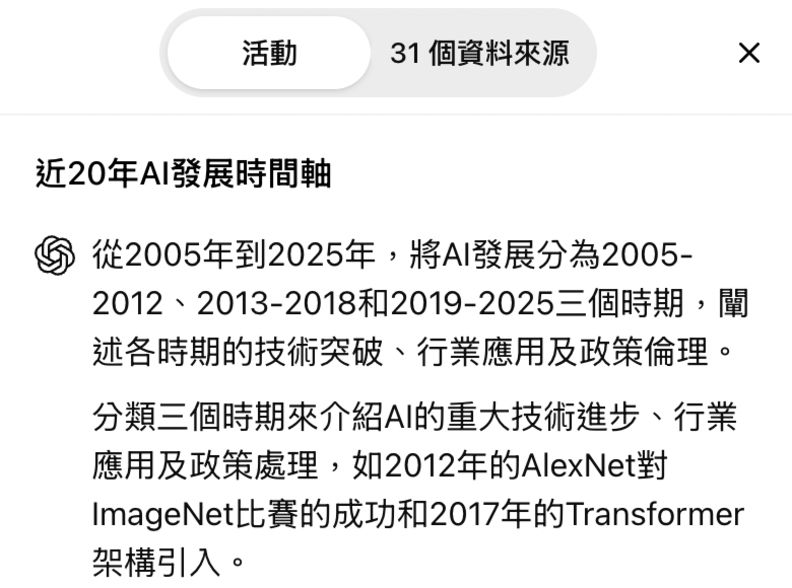
【ChatGPT】
ChatGPT在輸入指令後,會先詢問使用者想聚焦的分析方向和報告呈現格式。由於Grok和Perplexity不會反問使用者,因此這裡也不限制GPT的回答方向。
GPT的答案僅列出三個時期與三個關鍵事件,沒有額外撰寫前言和結論,也沒有以表格呈現,但整體而言內容清楚,也有逐句附上參考來源。


至於完整的思考過程和資料來源,GPT沒有將其放在報告之前,而是放在右邊的視窗中。
完整對話請見此連結。
實測2:比較各家AI公司優缺點
第二項實測想了解AI深入研究不同產品差異、以及找出最新資訊的能力,輸入的指令為「請分析目前最強大的5個大型語言模型優缺點及未來發展方向」。
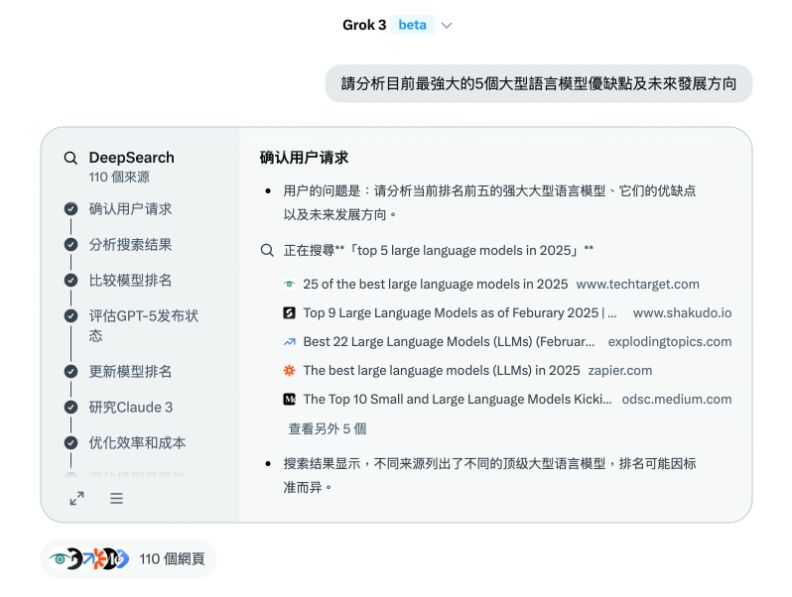
【Grok 3】
Grok 3選擇的五個模型為OpenAI o1、Claude 3、Gemini 2.0、LlaMA 3和DeepSeek V3,有些不是該公司的最新模型,例如OpenAI在1月時推出o3-mini、Anthropic在去年6月時推出Claude 3.5(目前最新的模型是24日發表的Claude 3.7,實測時尚未發表)等。
Grok 3在報告最後有附上表格,比較五個所選模型的性能。

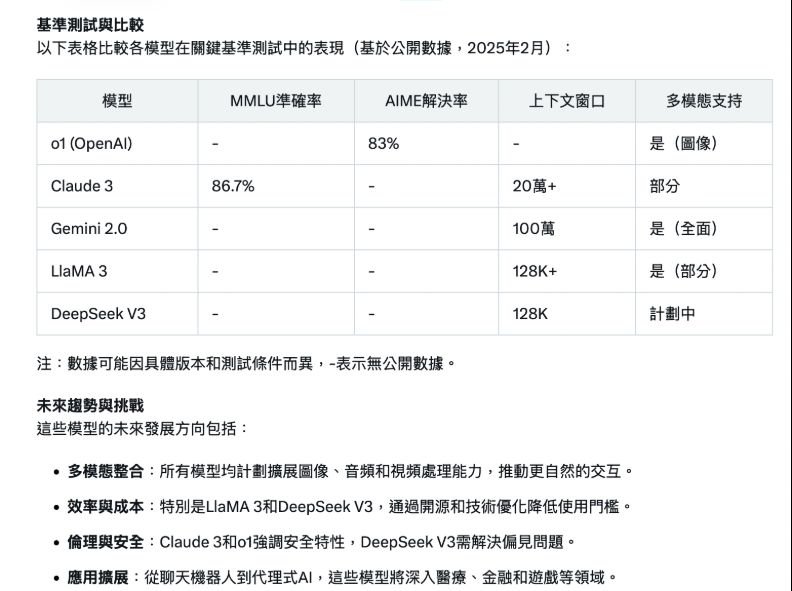
完整對話請見此連結。
【Perplexity】
Perplexity所選的模型為GPT-4o、Claude 3.5、Llama 3.1 405B、Grok-2及Mistral 8x22B,有些也並非最新模型,例如未寫到xAl最新的Grok 3模型,只有上一代的Grok-2等。其研究報告僅以段落形式分析每個模型,沒有條列式或整理表格。
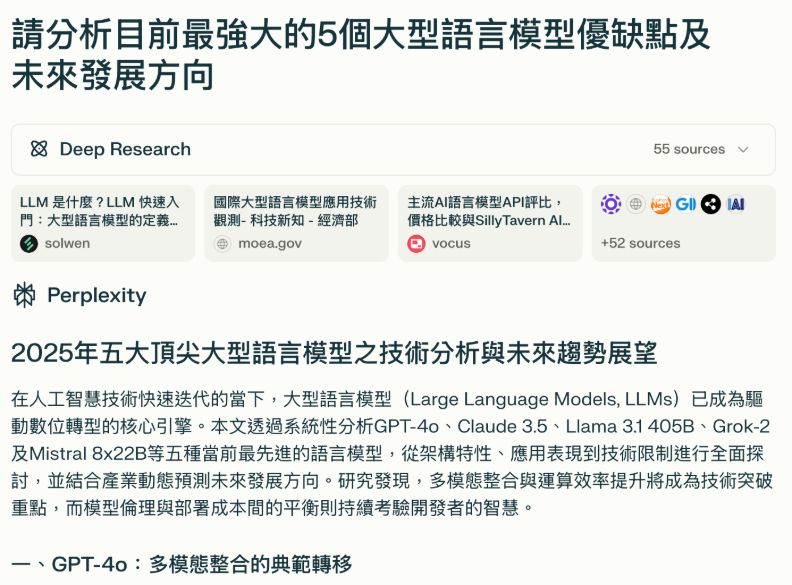

完整對話請見此連結。
【ChatGPT】
ChatGPT選擇的五個模型為GPT-4、Claude 3、LLaMA 2、Mistral 7B、PaLM 2,GPT-4為OpenAI 2023年推出的模型,可見其並未搜尋到最新資料。
其報告分項探討各模型的技術細節、性能表現、應用場景等,也會在報告中以粗體畫重點。但沒有附上結論,也沒有比較不同模型的表現。



完整對話請見此連結。
實測3:回答申論題
最後一項實測要求兩者回答申論題,並應用理論和數據,測試其撰寫學術報告的能力。指令為「請結合學術理論,從三個面向申論短影音對當代青少年的影響,並附上佐證數據」。
【Grok 3】
Grok 3從學業表現與認知發展、心理健康與幸福感、社交技能與關係三個面向探討此問題,每個面向引用兩個理論和兩篇論文。


完整對話請見此連結。
【Perplexity】
Perplexity從注意力機制重組、社交模式異化及價值觀形塑三個面向回答,在每個面向中又有兩個重點項目,將理論和數據整合說明,較像是學術文章寫法。
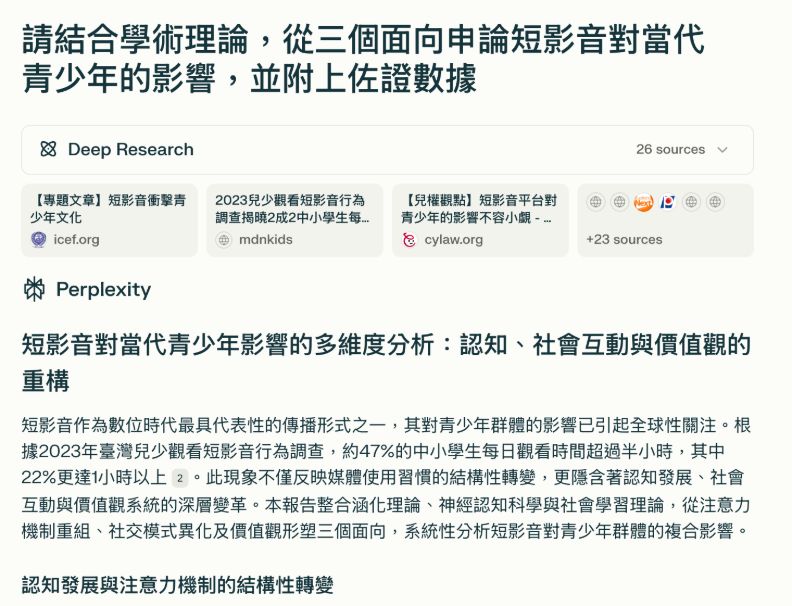
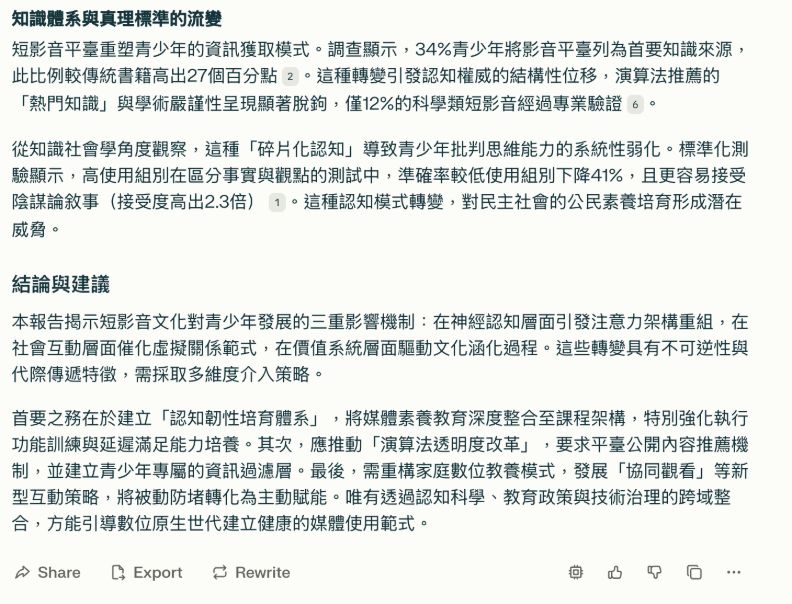
完整對話請見此連結。
【ChatGPT】
ChatGPT從心理健康、注意力與學習表現、以及社交互動與自我認同三個面向探討,與Grok 3所選的面向類似。其在分析三個面向時,沒有固定的架構,前兩個面向以段落形式呈現,第三個面向卻變成列點和表格。



完整對話請見此連結。
Deep Research實測3工具結論
以下表格統整了Grok 3、Perplexity和ChatGPT深度研究功能的各項表現和特色。本次實測的指令非常簡單,僅為了大致比較不同AI的回答狀況,不深入分析報告內容。此外,此表格僅供參考,其答案品質可能因指令細緻程度而不同。
回答速度 | 研究報告結構 | 參考資料語言 | 反問使用者 | 逐句標註來源 | 免費使用額度 | |
Grok 3 | 最快 | 完整,列點、輔以表格說明 | 英文 | X | X | O(一天10次) |
Perplexity | 中等 | 完整,較像學術文章寫法 | 中文 | X | O | O(一天5次) |
ChatGPT | 最慢 | 沒有前言和結論,有時架構不清 | 英文 | O | O | X(Plus以上用戶才能使用) |



