







近來Google和臉書接連在大語言模型驅動的對話服務出招。Google於9月時宣布更新Google Bard,串連Workspace提升個人工作效率,臉書則是推出能夠以語音互動且能夠生成圖片的聊天機器人,和ChatGPT打對台。OpenAI眼見對手頻頻出招,9月底也宣布已升級到GPT4的ChatGPT不再受到時間限制,現已開發讓ChatGPT訂閱戶可以在對話時,直接串連微軟旗下的Bing搜尋引擎,取用即時上網資訊,另外還有讀圖片幫你找解答與對話新功能!到底怎麼用?此文實測一次解。
ChatGPT 4現在能瀏覽網路資料,還能告訴你資料來源
OpenAI在今年5月時,其實就已經提供瀏覽網路的外掛(plug-in),只是當時搜尋速度頗慢,且沒有特別針對ChatGPT取用網路資料特別設計功能。OpenAI在推特上指出,它們收到許多用戶回饋,因此做出不少調整,例如遵循被爬蟲網頁的文件指示(robots.txt)以外,讓網站知道怎麼跟ChatGPT互動。
ChatGPT can now browse the internet to provide you with current and authoritative information, complete with direct links to sources. It is no longer limited to data before September 2021. pic.twitter.com/pyj8a9HWkB
— OpenAI (@OpenAI) September 27, 2023
Google曾在Google I/O 2023大會上揭示「搜尋生成式體驗」(Search Generative Experience),也就是以Google搜尋引擎收錄的資訊為基底,利用生成式AI精煉資訊,「從我們熟知的關鍵字搜尋,轉變為接近日常提問的感覺;就像是和真人對話,反覆追問的過程;從讓人自行判斷的結果條列,變成整理好的解答。」
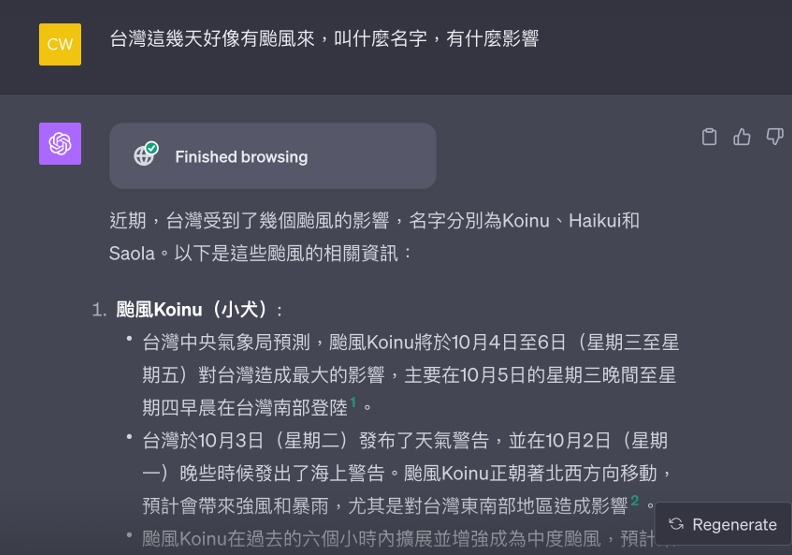
這次ChatGPT更新帶給人的感受也類似,結合Bing的搜尋功能,還有ChatGPT生成文字,便可以產出一篇整理文章。以台灣最近時事的颱風為例,我們向ChatGPT提問,而它整理出一篇完整回答。
另外,因為生成式AI的幻覺問題(hallucination),讓使用者格外重視信任ChatGPT和Bard生成的內容。Bard提供的解方是「驗證」,也就是先生成回答後,接著再利用搜尋引擎對比資訊,確認生成內容是否有資料可以佐證,藉此提供內容「可否信任」的判斷。
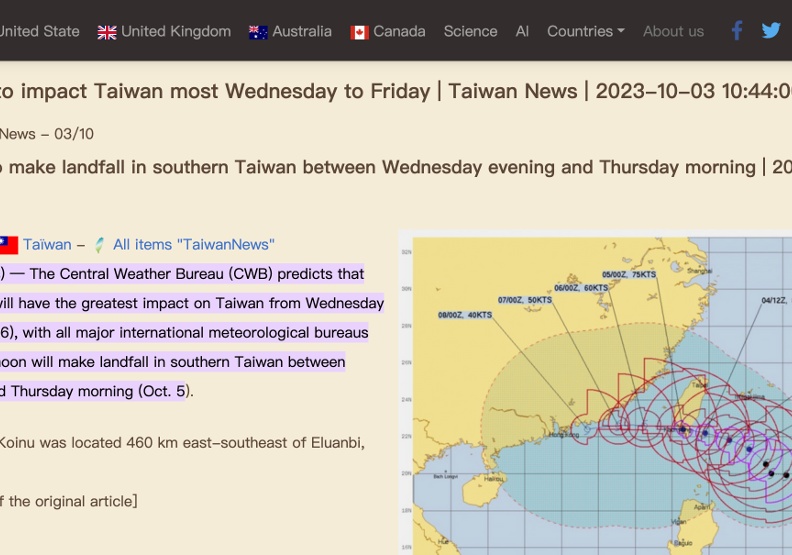
ChatGPT目前還沒進展到此階段,僅用單純的內容出處,讓使用者可以查閱,例如上面的颱風案例,就是在每段文字後提供超連結。點擊小犬颱風相關文字後,可以連結到生成內容的參考依據。
ChatGPT 4 多模態功能日益完善,不只語音對話還即將可以讀懂圖片
OpenAI在向大眾介紹GPT-4時,就曾提到過對於多模態(multi-modal)的野望。如今,當初勾勒的願景正在逐一實現。
OpenAI多模態與尖端研究部門主管(head of multimodal and frontier research)陳信翰(Mark Chen)在台灣演講時,曾指出「增加模型與真實世界的互動表現,並測試多模態模型的邊界,以及讓模型可以完成廣泛目標(general purpose)」都會是OpenAI接下來研究的重要課題。
OpenAI在9月底宣布,「ChatGPT現已具備視覺、聽覺和語言表達的能力。」
當初OpenAI展示GPT-4新功能時,曾經有個環節是使用者上傳圖表,讓模型判讀圖表中的資訊,還有使用者上傳照片,請模型指出照片中有何特別之處。現在,輪到一般民眾也能體驗這個功能了。
OpenAI表示,接下來的兩週內,將會把視覺能力提供給使用者。先行使用者們已經開始分享具備視覺能力的ChatGPT,究竟有多麽強大。舉例來說,有人拿了頂尖導演諾蘭(Christopher Edward Nolan)替《全面啟動》繪製的架構圖,上傳至ChatGPT做為視覺輸入(visual input),ChatGPT完全拆解了這張架構圖,逐一列出電影中的夢境層次。
ChatGPT Vision breaks down Christopher Nolan’s early diagram for Inception.
— Mckay Wrigley (@mckaywrigley) September 30, 2023
Best part?
The diagram doesn’t mention the word “Inception” once.
Crazy. pic.twitter.com/grPpTjvg3d
請ChatGPT看截圖,幫你抄程式碼
有人則上傳設計軟體Figma的截圖,並指定ChatGPT使用特定前端套件生成程式碼,ChatGPT憑藉著使用者介面截圖和程式碼範例,便生成出能夠運行的程式碼。
这位网友再次演示了用 ChatGPT Vision 可以从 Figma 截图并生成前端代码,他甚至指定了使用一个流行的前端库shadcn ui https://t.co/xCVTNun54v ,通过提供给ChatGPT shadcn上的代码示例,ChatGPT就能基于代码示例和UI截图,生成代码,运行效果和截图基本一致。
— 宝玉 (@dotey) September 29, 2023
视频加上了中文字幕 https://t.co/dqtLIl19G0 pic.twitter.com/k3Gk7SRDU4
除了視覺能力以外,ChatGPT也增加語音互動功能。使用者可以在Android和iOS版本的ChatGPT中,和ChatGPT對話。OpenAI表示,就模型輸出而言,它們利用文字轉語音模型,並和專業聲音演員合作,生成與人類聲音相似的聲音;以模型輸入來說,則是利用OpenAI著名的Whisper語音辨識系統,解讀使用者的話語。
以後,就能請ChatGPT說床邊故事給小朋友聽了。
還能生成圖像!DALL·E 3即將整合進ChatGPT之中
不讓Midjourney專美於前,OpenAI在官網中另外表示,DALLE·E 3即將整合進入ChatGPT中,預計10月就逐步開放大眾使用。現在已經有使用者搶先在OpenAI社群分享試用心得。
有用過Midjourney的使用者時常發現,模型有時候會忽視特定指令,或者誤解使用者意思,因此生成的圖片不符需求,想生成好內容就像抽卡一樣常常要看機率,雖然隨著版本迭代表現日益進步,但仍是使用者痛點,必須時常彼此交流如何精煉自己的提示工程(prompt engineering)技術,迎合模型,例如將提示詞限縮、一定要用特定架構撰寫。
OpenAI強調,DALL·E 3不會強迫使用者學習如何下好指令。也就是說,即便使用者用的是我們日常可見的自然語言,模型也完全能夠理解指令,生成對應圖像。
這個進步反映出,新技術剛開始出現時的技能壁壘,很快就不存在了。提示工程師或許能夠掌握高超的與模型對話技能,但就像OpenAI這次更新一樣,「只是會對話」的功能旋即被「更懂使用者意圖」的模型給取代。
若要跟著浪頭飛,恐怕還要學得更深、懂得更廣才行。



