以低成本打響知名度的DeepSeek,亦掀起產業應用的開源模型革命。在人工智慧學校春季論壇上,業界領袖、學界專家怎麼看這其中蘊含的風險與機會?面對快速變化的產業地景,台灣該如何善用外部資源及既有基礎,實現在地創新?
被視為「國運級」科技突破的DeepSeek日前低調更新V3模型,外界亦緊盯R2的發布消息。但年初時震盪國際市場的R1模型,可能只是更大規模產業變化的開端。關鍵是成本,更是開源。
人工智慧學校(AIA)27日以「開源模型的衝擊與對應」為題,舉辦春季論壇。於開場致詞中,數位發展部政務次長林宜敬直言,談開源模型,大家都知道想談的重點就是DeepSeek,從技術、產業到政治面,「DeepSeek對台灣的衝擊非常大。」
這一方面對美國為首的民主陣營自認具有的領先幅度敲響警鐘,但另一方面也為台灣揭示新機會。一是成本較低,為AI新創保留更多盈利空間。二是壓縮訓練資料用量,在訓練方法上有可以學習之處。
曾於「零一萬物」負責經營開源及開發者生態的林旅強,分享在中國的經驗及產業觀察。現為獨立顧問的林旅強是中國開源社群「開源社」共同創辦人,先前曾任職華為,在中研院服務時期,曾為資訊科技創新研究中心下的「自由軟體鑄造場」(OSSF)進行研究工作。
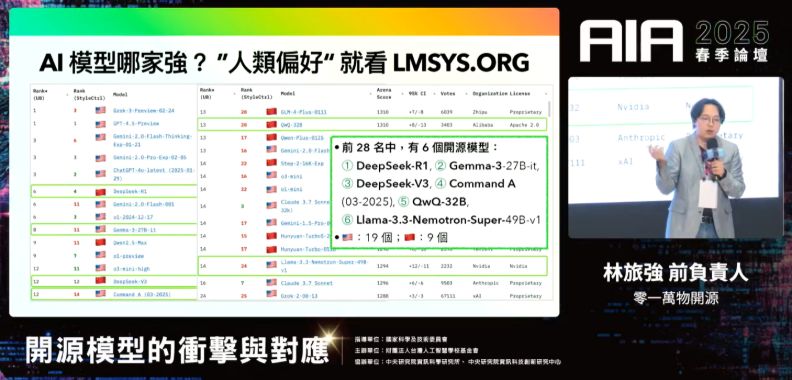
有多年經營開源社群經驗的林旅強指出,DeepSeek為「開源」再度打響國際名聲,中國對開源模型的觀點也逐漸轉變。他表示,中國開源文化起步得比台灣稍慢。先前產業氛圍較看重閉源模型,認為「最強的模型不會開源」。包括零一萬物在內,許多團隊選擇開源較小版本模型,表現最佳者維持閉源。
然而,在DeepSeek選擇開源自家推理模型後,表現不如R1的模型閉源已沒有意義,也推動更多團隊投向開源,最引人注目者可能是百度。過去擁護閉源模型的執行長李彥宏曾在2024年表示「開源模型是智商稅」,但百度已在2月宣布下一代文心大模型系列將會開源。
林旅強認為,在大廠中,阿里雲的「通義千問」系列可稱是開源模範生。字節跳動的豆包大模型未來也可能轉向開源。
AI大模型「六小虎」之一的零一萬物,已做出策略轉向。在先前放棄訓練萬億級大參數基礎模型後,3月進一步宣布萬智企業大模型平台,直接接入DeepSeek,為企業提供後訓練、強化學習等服務,填上基礎模型不足以服務企業個別需求的缺口。
這是看準具有低成本優勢的開源模型,將加速企業應用及私有部署的擴散。林旅強建議,台灣亦可跨出提供硬體算力的範疇,搶進符合企業需求的地端AI解決方案市場。
林旅強認為,模型來自哪一國不是重點,重點是模型是否開源?使用效果是否理想?是否能符合場景需求?若能使用在地語料進行模型微調,並在本地部署,確保資料安全,可以善用開源模型釋放更大應用潛能。
正視開源模型風險,同中求異取得競爭優勢
在安全議題上,AIA秘書長侯宜秀指出,至少存在資安(security)與安全(safty)兩個面向。資安防護到位,不表示安全疑慮也完全解除;這可能包括模型的價值觀對齊、不具偏見等。DeepSeek在資安面向較弱,但在對齊中國社會主義價值觀上則表現不俗。
侯宜秀表示,確定使用案例,是進行模型風險管理的第一步。也就是先釐清要使用AI來做什麼。若是準備應用於醫療等講求準確、專業應答的場景,就必須特別注意生成內容的品質。
長庚大學智慧運算學院院長許永真提醒,開源雖有加速創新、降低壟斷及民主化等正面效益,在使用開源模型時,需深入了解其優、缺點與風險因子。即便是許多閉源模型也存在安全,不宜認定在地端運行開源模型就沒有安全疑慮。

在機會層面,台大資工系教授洪士灝指出,適合台灣現階段的策略是善用開源模型作為基礎,結合既有強項,在「同」中求「異」,發展出具有競爭力的專家推理模型。
洪士灝解釋,在各家模型能力沒有太大差異的情況下,性價比會成為主戰場。可以將成本壓得較低者,將具有優勢。善用開源模型,就是一個壓低成本的選項。
台灣的晶片製造等硬體產業,以及精準醫療,可以是發展專業模型的切入點。但這將需要可以在垂直產業中訓練專家模型的人才,包括懂得用AI加值百工百業的人才,以精通AI模型、系統技術的人才。而這在國內外都是相當搶手的。
這呼應AIA的核心要務。AIA校務長蔡明順表示,開源將加速大語言模型的企業應用與垂直產業模型發展。在此認知基礎上,AIA將持續推動各類別的AI人才認證。在應用大語言模型執行行政任務的工程級認證上,也將發布相關指引。
開源是國力的延伸,也是軟實力的展示。在台灣既有的開源基礎上,進一步賦能參與者,也鼓勵企業投入經營開源生態系,會是政府可以共同挹注的目標。