台灣人工智慧實驗室將自家專精繁中語境的「FedGPT」推入AI Agent時代,為企業簡化、加速AI代理的落地過程。在大型基礎模型能力相差無幾的現況,企業自擁資料如何在「聯邦式」資料治理模式下展現潛能?到底這種模式是什麼?為何被看好適合台灣生態?
AI代理來勢洶洶,台灣人工智慧實驗室(Taiwan AI Labs)25日宣布,將耕耘已久的FedGPT升級為FedGPT AgentTeam。在軟硬整合的基礎上,進一步為企業提供易於AI代理落地的平台。
自推出以來,FedGPT以不需資料上雲的「聯邦式」資料治理模式,受到重視資料隱私及安全性的行業青睞。醫療、金融與公部門等領域,是常見的早期採用者。
邁進AI代理時代,台灣人工智慧實驗室創辦人杜奕瑾樂觀預測,下一步落地會「全面展開」。他受訪表示,產業導入通常有先後順序。對資料隱私要求特別高、也較有資源者搶先部署,但隨著相關法規方向逐漸明朗,所有的產業都會需要這樣合規、安全且適用台灣情境的AI服務。
簡化設計流程,推動AI Agent進入工作流
AI代理要能發揮應有的效能,必須整合進入企業工作流。這也昭示著AI的企業應用,正從獨立試點計畫邁向打造人機協作團隊的趨勢。
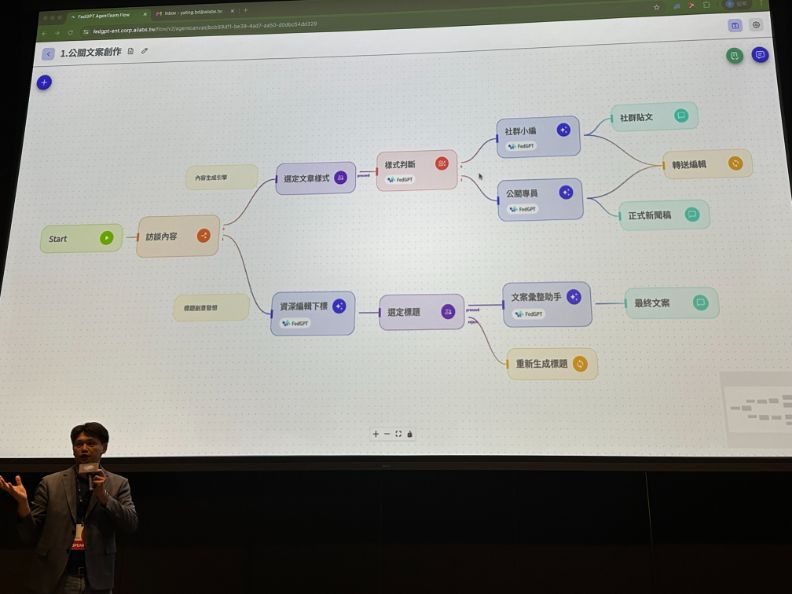
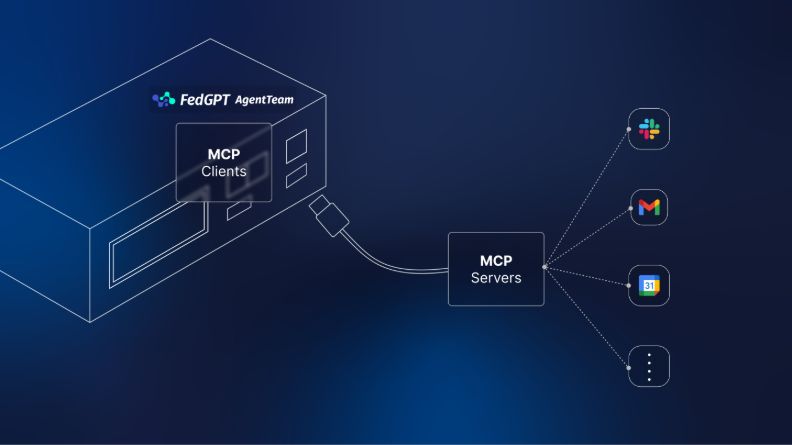
對此,台灣人工智慧實驗室的回應是「AgentTeam Flow」。在近似n8n的簡潔介面上,企業員工可自行設計工作流程,以自然語言觸發多代理協作,也能在MCP、A2A的協議框架上串接外部工具。
杜奕瑾解釋,「以前大家覺得agents只有IT部門可以做。但我們就是把它簡化到一般business需求的人就可以建立自己的agents。」
讓真正執行業務流程的人,來設計最能為自己增能的代理流程,也是較合理的做法。即便員工缺乏工程背景,也有代勞數據整理的AI代理協助。
同樣地,「AgentTeam Tuning」在AutoML(自動化機器學習)的主動學習基礎上,支援企業進行持續的、專屬的多模態模型微調,而不需要專業的AI工程師執行。
「AgentTeam RAG」則支援多模態的知識檢索與生成,強化企業洞察。在回應上也有拆解問題的能力,可加速回應簡單問題,或逐步破解較複雜的問題。
提供另一種地端解決方案,保護資料隱私也保護資料擁有者
在市場上,FedGPT以優化繁體中文表現、適合機敏資料的地端運行為主要特色。杜奕瑾表示,在經過千億詞元規模的台灣語料訓練後,FedGPT能以小搏大,對台灣語境的理解勝過一般基礎模型,輸出也較不易受到中國官方資料的影響。
台灣人工智慧實驗室認為,比起大量網路資料訓練而成的雜學博聞型基礎模型,一個懂得謹言慎行、符合特定產業需求的小專家模型,對企業來說是更實用的。
杜奕瑾指出,讓現前流通的大語言模型成為可能的網路可用資料,已經幾乎用罄,但企業內部資料還有很大的應用潛力。這也是聯邦式機制可發光發熱之處。
他舉例,金融機構的內部資料可用於訓練防詐騙、反洗錢的模型,醫療機構的資料也可打造X光片辨識模型。在授權機制的保障下,提供資料訓練模型的醫院,可在模型部署使用時,獲得授權金的回饋。
聯邦式機制,為何適合民主台灣?
杜奕瑾認為,這種聯邦式、多專家的機制,既能保護資料與資料擁有者,也能保障這個世界的多元性與民主性,而非讓主流平台贏者全拿。由於價值觀接近,台灣人工智慧實驗室的努力也特別受到歐盟重視。
杜奕瑾相信,若能在聯邦式平台上成功打造台灣AI代理的生態系,亦能向全球展示一種典範。
目前FedGPT已導入醫療、金融、教育、公部門等領域,客戶包括花蓮慈濟醫院、輔大醫院、東華大學、台新銀行等。
誠然,結合軟硬體的AI一體機初始成本較依量計費的雲端解決方案高上許多,但台灣人工智慧實驗室產業方案總經理黃佳欣認為,這在長期看來可能是更具成本效益的做法。
黃佳欣向《遠見》解釋,在生成式AI時代,不會只有少數解決方案,而應該有多種方案滿足不同企業需求。從前期的反覆測試、經驗累積,到後期的持續優化,企業都能在一體機上進行,這提供了與雲端完全不同的服務模式。
杜奕瑾也提到,隨著AI代理在企業內部落地,員工們將轉型為「AI代理的管理者」。被淘汰的是無法跟上時代的技能,而不必然是人類員工。