








中研院詞庫小組釋出的繁體中文大語言模型,因為對答時不斷吐出「中國式回應」,甚至曾回答國慶是10月1日!難怪引發關注人工智慧者的熱烈討論。大語言模型應該反映什麼樣的價值?台灣要不要開發本土大語言模型?《遠見》訪問「台版ChatGPT」計畫TAIDE顧問李育杰,以及微軟AI領域最有價值專家孫玉峰,梳理整起事件。
10月初,中研院詞庫小組(CKIP)在程式碼社群暨管理平台GitHub上,釋出可供商用的繁體中文大語言模型(LLM)CKIP-Llama-2-7b,本是美事一樁。然而,有使用者實測時發現,模型生成內容明顯脫離台灣脈絡,針對國慶日提問模型回答「10月1日」,請教保險制度問題則回答「五險一金」,就連領導人也變成習近平。
因為引發爭議,中研院發現後迅速將模型下架,並在官網發布聲明。內文強調此項研究並非「台版ChatGPT」,實為花費僅30萬元的個人小型研究成果;此外,模型專為處理特定任務所開發,因此訓練時有採用簡體中文資料集。
這起「模型翻車」事件,可以分為三個層次討論。
第一層的問題是「資訊揭露不夠充分」,反映出開源文化慣習與圈外民眾認知的衝撞。
第二層的問題是「模型回答脫離在地脈絡」,涉及AI系統與人類價值對齊,以及台灣是否應該開發本土化語言模型的辯論。
第三層的問題是「國家進場開發LLM的必要」,背後則要討論企業和國家發展LLM的分工。
除了釐清事實性問題,例如挑選資料集判準、訓練與微調模型的技術細節以外,開發大語言模型的價值性問題,更值得關注,因為技術與社會不是互斥,而是緊密纏繞。
層次一:當開源文化與民眾認知碰撞
此事CKIP模型事件掀起軒然大波,起因於幾項認知偏差:CKIP模型不具通用性、LLM不適合回答事實性問題、開源文化與民眾認知發生碰撞。
孫玉峰解釋,CKIP模型其實是針對「明朝與清朝人物分析」任務微調,但釋出模型時的宣傳為商用繁體中文模型,沒有交代清楚,事後中研院才補充說明。再加上民眾可能不熟悉LLM會產出「幻覺」,使用戴上「中研院」桂冠的模型,會有一定期待。發現答案都是對岸脈絡時,因此引發反彈。

另外,有許多開發者習慣開源精神,得到成果後及早發表、與社群共享,CKIP過去就曾開源自然語言模型與工具,造福無數開發者。李育杰強調,他非常支持將模型開放給更多人使用,但開發者必須理解產品有其後果。
當新技術離開實驗室、走進大眾視野,對社會造成衝擊的潛力,恰好能和OpenAI釋出GPT-4前經過6個月安全測試對比。李育杰指出,人們存有一套熟悉的價值判斷,認為什麼是對、什麼是不對,但CKIP模型產出和台灣社會認知價值差異太大,「你拿了一個中國的知識系統到台灣,就格格不入。」
對於解方,孫玉峰和李育杰同樣建議,釋出新成果時應標示用途、表明進度,並事先將衝擊納入考量。
層次二:模型生成回答脫離在地脈絡,是問題嗎?
使用者之所以看到「國慶日為10月1號」,主因為CKIP利用簡體中文資料微調模型。不用繁體中文的根本原因,就是缺乏大量標註品質優異的繁中資料有關。
李育杰參與、由國科會推動的「TAIDE」,以建置台版基礎模型為目標,其中一個重要工作就是搜集與標註繁體中文語料。他表示「語言累積知識也傳承經驗,模型裡面乘載社會文化與價值,」因此有必要開發本土化LLM。
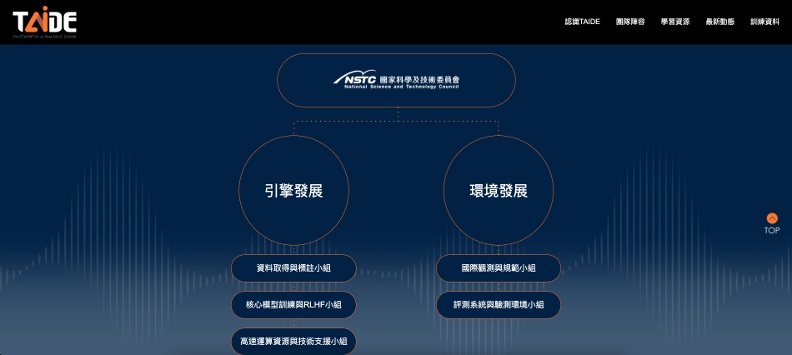
李育杰以GPT模型訓練資料集為例,繁中僅占不到1%,因此模型產出偏向英文與西方脈絡。雖然台灣可以翻譯簡中資料,但用語和內嵌知識都不符合台灣脈絡,所以TAIDE才會投入資源累積繁中資料集。
對於開發本土語言模型的必要性,孫玉峰持保留態度。
從LLM的實用性角度來說,例如客服使用大量對岸用語,可能影響使用體驗,這可以利用技術,像是在模型的回應層調整,用不著從頭開發;若從價值相關論述來看,孫玉峰反問,「保留文化為什麼一定要用AI?」
他解釋,文化和社會價值觀當然重要,但LLM本質並不是用來承載人類價值觀,而且人工智慧尚且無法「處理」社會價值,「不是說開發技術就要忽略社會脈絡,但人工智慧其實還沒發展到這個程度。」若遇到演算法偏見,可以視應用場景宣告與提醒使用者應該注意。
層次三:政府與企業,誰應該開發大語言模型?
除了探討本土化語言模型的必要性,另一個熱烈議論的題目是,政府是否有必要投入大語言模型開發。
孫玉峰認為,開發與否,端看政府對台灣科技的想像藍圖,有沒有將LLM視為產業發展重點。他個人認為,若真心想投入,應投資在基礎建設,例如標註資料、提供算力等。「我的想像不是一支國家隊,比較像是提供資源的平台,讓想要參與的人走得更順。」
他也補充,政府版做出的LLM品質有多好不是重點,更重要的其實是,以國家之力開發LLM,過程中對產業帶來幫助,不管是培養生成式AI人才,還是積累過程中踩過的坑,都能讓開發者借鏡。
身為國家隊成員,李育杰的說法和孫玉峰仍有呼應之處。他將TAIDE計畫定位為引擎,「(引擎)不是完整產品,外面還要加殼。」至於要加怎麼樣的外殼,就交給垂直應用領域決定。
李育杰理想中的分工是政府做基礎模型,業界負責應用端,因為後者具有領域知識,也有各自明確角色。他也強調政府開發LLM絕不是與民爭利。「如果市場效率比較好,那企業燒錢開發的事情應該早就發生。」然而,就像OpenAI轉型接受微軟注資一樣,LLM雖有巨大潛力,但開發期程長,「這種基礎層的事情,企業看不到短期利益,投入都是風險。」
這起引發AI圈外人熱議的事件,日後回望可能只是過眼雲煙,卻是一個讓世人思考本土化語言模型發展的好機會。



